ML Lecture 11: Why Deep?
DNN 會表現比較好是因為參數較多?
試著讓單層NN與DNN參數相同
- 單層NN很矮胖
- DNN很高瘦
結果還是DNN表現比較好
為何參數相同狀況下,DNN還是比較有效?
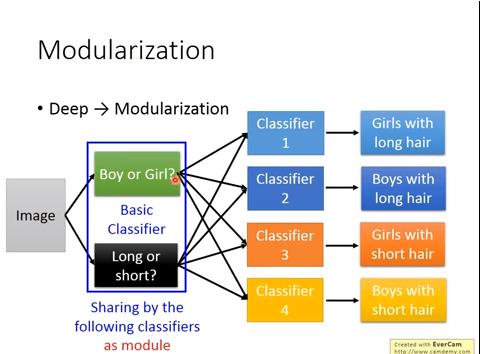 ex: 想要分類器判斷長髮男、短髮男、長髮女、短髮女
ex: 想要分類器判斷長髮男、短髮男、長髮女、短髮女
- 模組化
- DNN可以在前面的layer先使用簡單的分類器(ex: 男女? 長短髮?),後面的layer再經由前面的layer組合成複雜的分類器,省去重複的工作
- 因為前端layer的 classifier 比較簡單,反而可以使用較少的training data做出不錯的分類結果
- 這和我們對deep learning的認知是相反的!!!(deep learning需要較大量的data)
Modularization - Speech
這部分沒懂
Universality Theorem
任何連續函數f 都可以被單層的NN給實現(只要hidden neurons夠多)
- 但是這個理論沒告訴我們的是:使用更深的結構能夠更有效率(使用較少的parameter、與較少的資料就能完成)
- 較少的參數與資料可能也代表了比較不容易overfitting
Complex Task

Do Deep Nets Really Need To Be Deep?(by Rich Caruana)
有人做了個實驗:比較單層NN與DNN,在兩者參數量相同時,DNN表現較好,但是現在把單層NN的input data,label換成DNN的output時,單層NN可以做得比原先還要好,甚至逼近DNN的結果。