Youtube
為何不用 supervised learning 就好

- objective function 無法對 做偏微分,不能 BP
- supervised learning 必須有正確的 label,然而連人類都不確定正確答案是什麼
- learning from teacher
- 沒有老師
- learning from experience
Alpha Go is supervised learning + reinforcement learning.
Learning a chat-bot - Reinforcement Learning

Deep Reinforcement Learning for Dialogue Generation
RL包含兩種方法
- Value-based
- Policy-based
More applications

Policy-based Approach - Learning an Actor
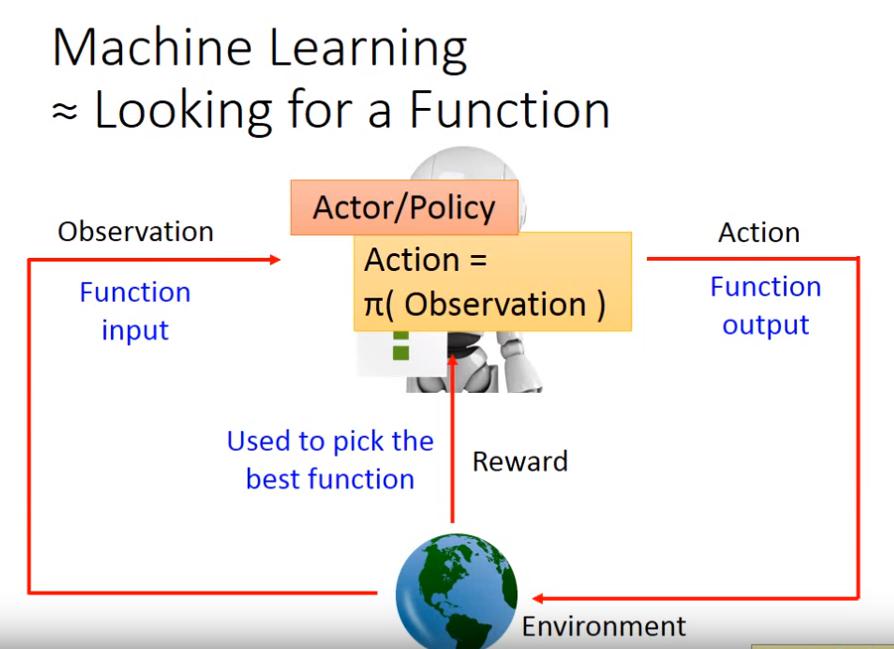 當Actor就是NN時,就叫 Deep Reinforcement Learning
當Actor就是NN時,就叫 Deep Reinforcement Learning
: episode, 一整場遊戲 : state, 其實就是機器對環境的 observation : actor : actor 的 parameter : action,會對環境造成一些影響,於是就有了 reward : reward
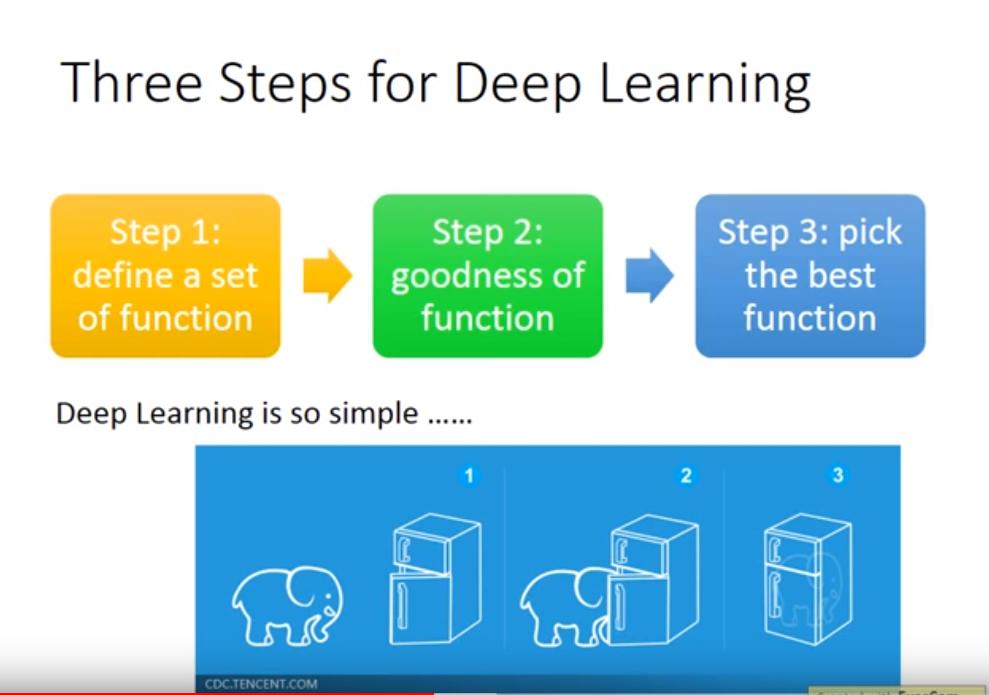
DL 三步驟 => 套用在 DRL
- define a set of function => Neural Network as Actor
- goodness of function => Goodness of Actor
- pick the best function =>
i. Neural network as Actor
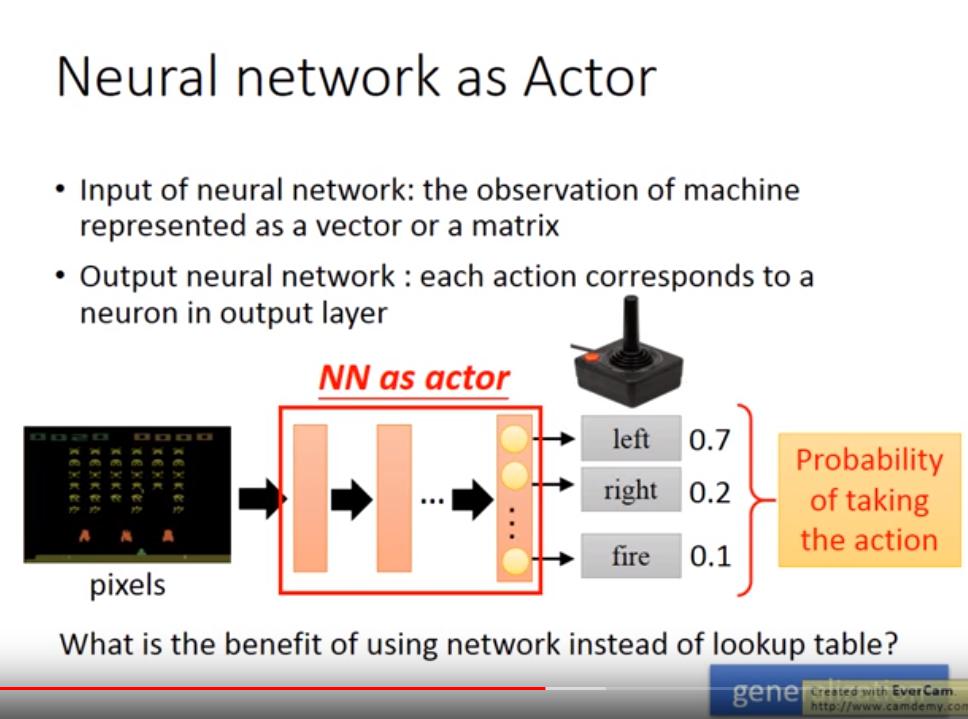
- input: machine 觀察到的 matrix
- output: 任何可能的 action (action 有幾種,output 就有幾維)
- 通常每個 action 會有一個機率
ii. Goodness of Actor

- : 某個 actor 決定做 action 的 function?
- : 該 actor 某次玩遊戲的結果
- : 該 actor 玩遊戲得分的期望值,也是評估 actor 好壞的標準
- 在第 t 時間點的順序:
- 觀察到
- 決定採取 action
- 得到 reward

- 一場遊戲可以用 來表示,可以視為一個過程 (trajectory)
- 那這個過程其實是一種機率分布,因為任何過程都有可能出現
- : 該場遊戲的 total reward
- 影片有誤,應為 T 而不是 N
- : 選定一個 actor 的參數,某過程所出現的機率
- : 給定一個 actor 的參數 ,所有可能的路徑所產生的 reward 的期望值
- 但是不可能對所有的 作加總,因此取近似值,讓 玩 N 場遊戲,將 reward 做平均 (),也就是使用 sampling 來近似
- 這個式子似乎和 GAN 做 sequence generation 的式子幾乎是一樣的,只是 不需要可以微分 (by DRL Lec1)
iii. pick the best function
- 目標就是最大化


- 和 無關,因此不需要做偏微分
- 因為
- 可以用 sampling 做近似
- 那剩下的問題就是計算


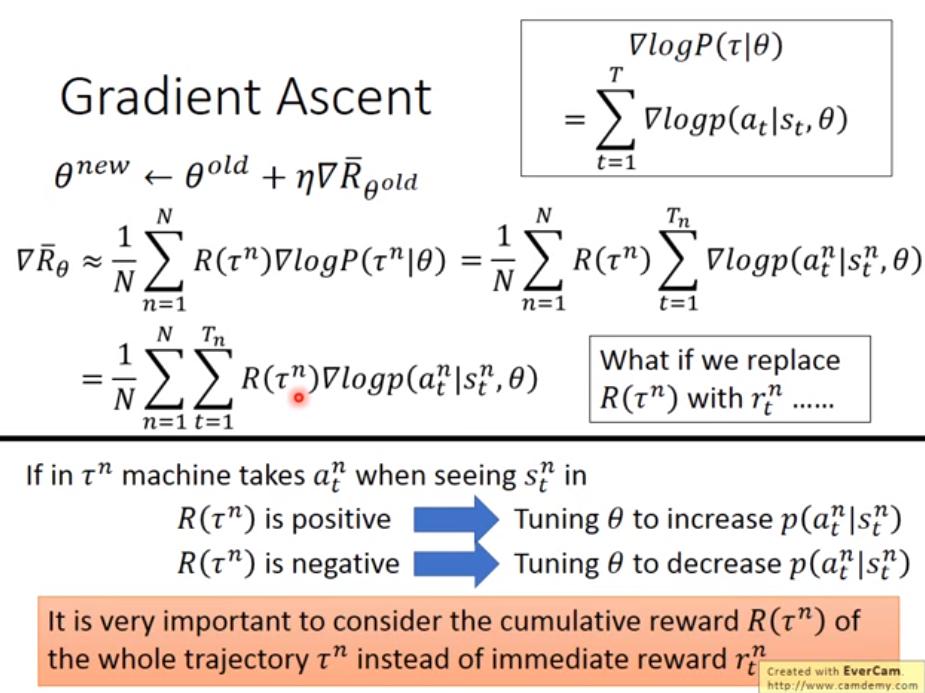
- 很直覺,如果某 state 採取某項行動導致最終的總 reward 是正的,就提高該 action 的機率
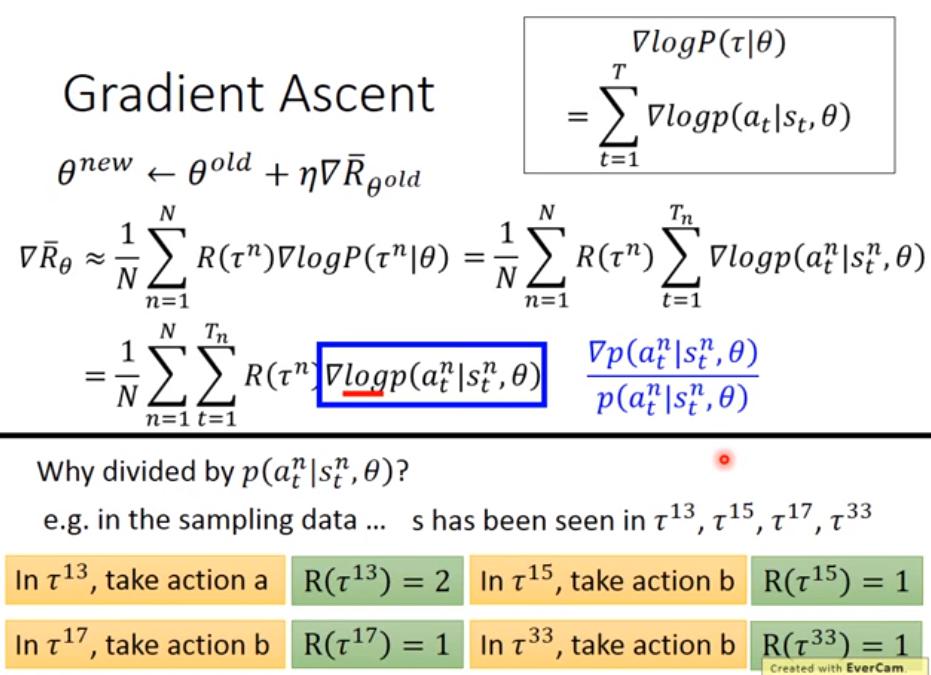
- 為何要取 log 呢? 其實這也是可以解釋的
- ,為何要除以 p 而不直接取 gradient 就好呢? 如果只取 gradient,當某個 action 的出現機率比較高,那 gradient ascent 就會更傾向於提高該 action 的機率,即使他得到的 reward 並不多。
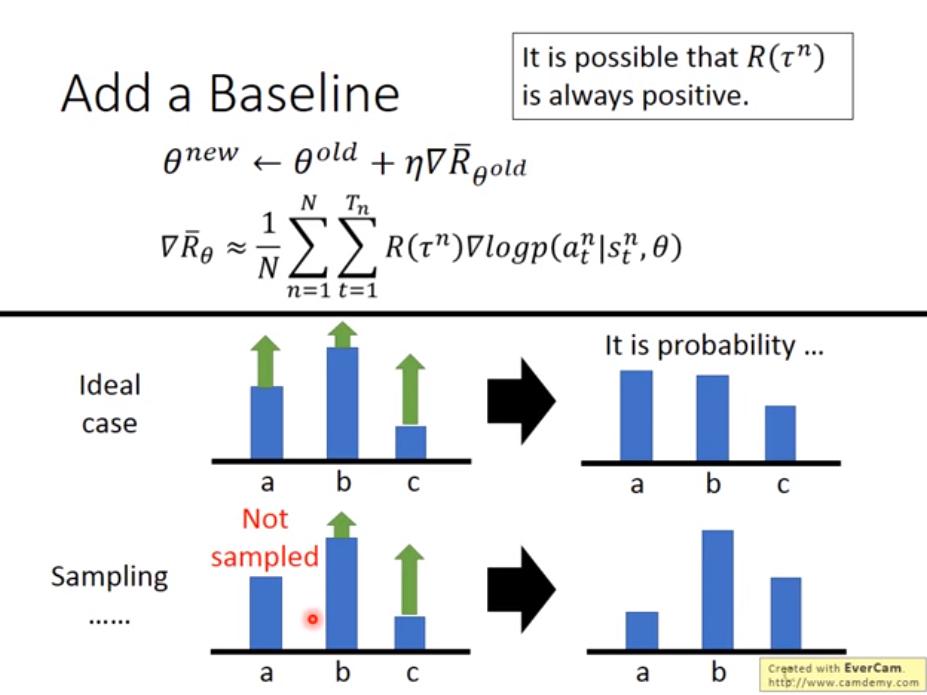 如果所有 action 的 reward 都是正的,雖然每次更新都會提升所有 action 的值,但是能達到比較大 reward 的 action 仍然會提升比較多機率 (因為機率會做 normalize),這是理想狀況。
然而實際狀況我們使用 sampling 的方式去逼近 ,因此可能會沒有 sample 到某個 action,導致該 action 的機率更新後變得更小 (因為所有 action 的值都增加了,但是沒有 sample 到的沒增加)。
於是我們希望 有正有負,因此減去一個 b,可以將 b 視為 baseline,我們可以自己訂。如此一來,有 sample 到的 action 就不會都只增加機率,沒 sample 到的 action 相對來說就不會只減少機率了。
如果所有 action 的 reward 都是正的,雖然每次更新都會提升所有 action 的值,但是能達到比較大 reward 的 action 仍然會提升比較多機率 (因為機率會做 normalize),這是理想狀況。
然而實際狀況我們使用 sampling 的方式去逼近 ,因此可能會沒有 sample 到某個 action,導致該 action 的機率更新後變得更小 (因為所有 action 的值都增加了,但是沒有 sample 到的沒增加)。
於是我們希望 有正有負,因此減去一個 b,可以將 b 視為 baseline,我們可以自己訂。如此一來,有 sample 到的 action 就不會都只增加機率,沒 sample 到的 action 相對來說就不會只減少機率了。
Critics

Three kinds of Critics
