ML Lecture 20: Support Vector Machine
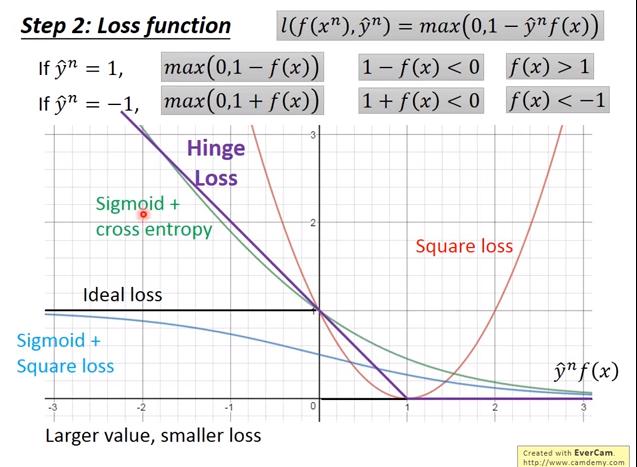
- 先以+1和-1表示兩個分類
- 表示第一筆資料到第n筆資料的label,值為+1或-1
- 我們期望 與 的乘積越大 越好,因此 越大,loss應該要越小
- 理想狀況是: 為正,則loss=0,為負,則loss=1,但是這個loss function無法微分,不能做gradient descent
- hinge loss: 只要 loss就是0,否則 越小,loss越大
- hinge loss 比較不怕 outlier
- 使用 hinge loss,當 時,只要 ,loss就是0;當 時,只要 ,loss 就是0
Linear SVM
- hinge loss 是 convex function
- regularization term 也是 convex function
- 相加仍為 convex function,gradient descent做起來相當簡單
與 logistic regression 唯一的差別是 loss function ,使用 cross entropy 就是 LR,使用 hinge loss 就是 linear SVM
可以有deep structure
也可以使用 gradient descent 解
gradient descent
 結論:
結論:
- depends on 參數 , 可以用 來代替
Linear SVM - another formulation (我們熟悉的 SVM 樣貌)

注意上圖兩個紅框框裡面的式子代表不一樣的意義
- 但是因為 loss function 要 minimize ,下面的紅色框就和上面的紅色框相同了
損失函數
- : hinge loss,即
- : regularization項
現在把 hinge loss 換成 ,即
而我們想 minimize loss 的時候, 這件事等同於
- 即
也就是說當我們無法達到 時, 可以放寬我們的標準(根據2式),故 又名 slack variable
Dual Representation

而最後解出來的 w 可以視為 data point 的 linear combination,即
WHY?
一般會使用 Lagrange Multiplier 解出之前提到的式子來證明,不過現在用 gradient descent 的觀點來看這件事
Gradient Descent 對於第i維的w,update
也就是
以 hinge loss 而言,大多數的 會等於0,也就是 中大多數的 會等於0,只有幾個 data point 的係數不為0,而係數不為0的那些 ,就被稱為 support vector。 若w初始化為0,則最後得到的w會是 data point 的 linear combination。而使用 data point 的 linear combination 做為w的好處是,可以使用到 kernel method
kernel method
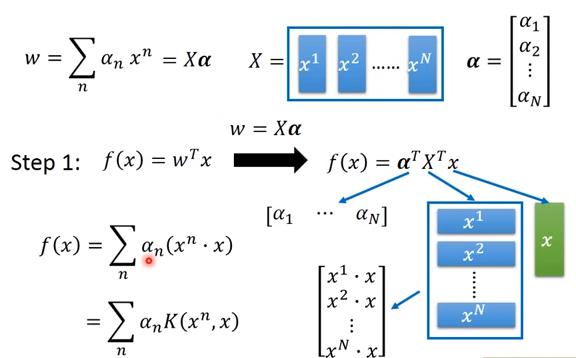 ,
所以
我們又可以把 寫成
因此
中,只有是未知的,也就是說我們的目的是找出使得 loss function 最小
,
所以
我們又可以把 寫成
因此
中,只有是未知的,也就是說我們的目的是找出使得 loss function 最小

因此我們只需要知道 是多少,並不需要知道 這個 vector 是長什麼樣子
Kernel Trick
當我們要把所有的 transform 成 時,kernel trick 很有用 Q: 的定義就是兩個 vector 做完 feature transform 之後的內積 嗎???
舉例 1
- 這是土法煉鋼的算法
- 我們可以把上面那個 的結果轉換成 ,這樣可以省下許多計算
- 個人理解:假設 為 維的 vector; 為 維的 vector,則計算 和 都需要 次計算、計算 需要 次計算。因此一共至少要進行 次計算
- 而直接計算 則只需要 次計算
舉例 2

- 把 x 的部分串成一個 vector 就是
- 把 z 的部分串成一個 vector 就是
舉例 3 - Radial Basis Function Kernel
如果把 視為一個 kernel ,則 feature transform 的維度會是無窮大,為什麼?

- 只和 有關,因此我們用 表示它;同理,我們用 來表示
- 把 用泰勒展開會得到後面那行的結果 (可以視為無窮多維的 feature inner product)
RBF kernel因為是投射到無窮多維,所以比較容易overfitting
舉例 4 - Sigmoid Kernel
Sigmoid kernel 就像是單層 hidden layer 的 NN,而 neuron 的數目相當於 support vector 的數目

自訂 kernel function
也可以自訂kernel function,用類似similarity方式定義
- 當 x 是 structured object,很難設計一個 ,很適用 kernel function
- 而 是否可以視為兩個 feature transform 的 inner product 可以用 Mercer's theory 檢查。

