Youtube
通常有兩種 Approach
Direct Transformation
- Input 和 Output 沒辦法差太多
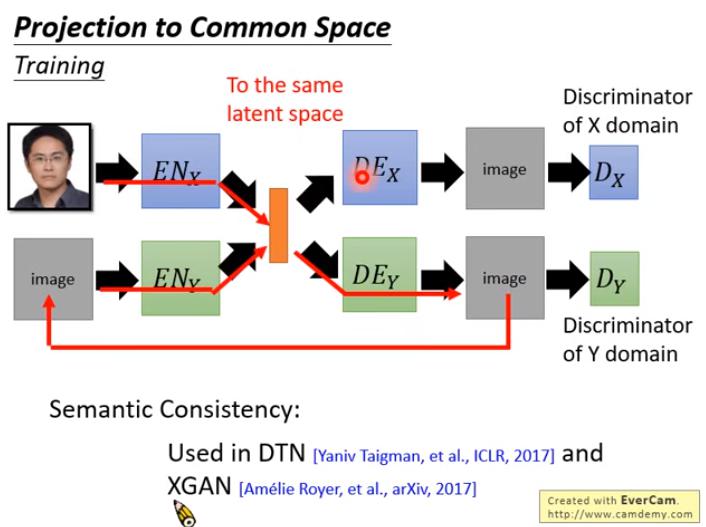
Projection to Common Space
- Input 和 Output 可以差很多
Direct Transformation
CycleGAN 的問題: CycleGAN, a Master of Steganography 表示,A轉B 的generator 可能有很強的能力將原圖的一些細節資訊藏在 output 的圖中,然後 B轉A 的 generator 再 reconstruct 回來
- 我個人認為在 output 加個 noise 應該就可以解決了?
CycleGAN 的一個 trick (YT 留言區)
StarGAN: for multiple domains
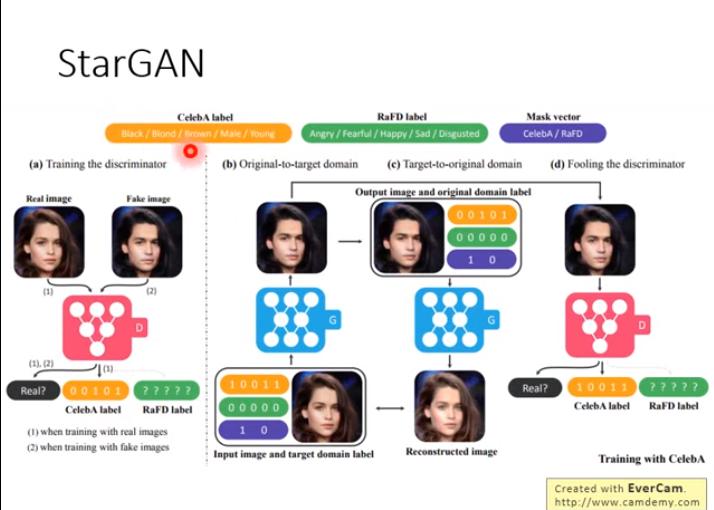
- domain 是可以重複的
Projection to Common Space
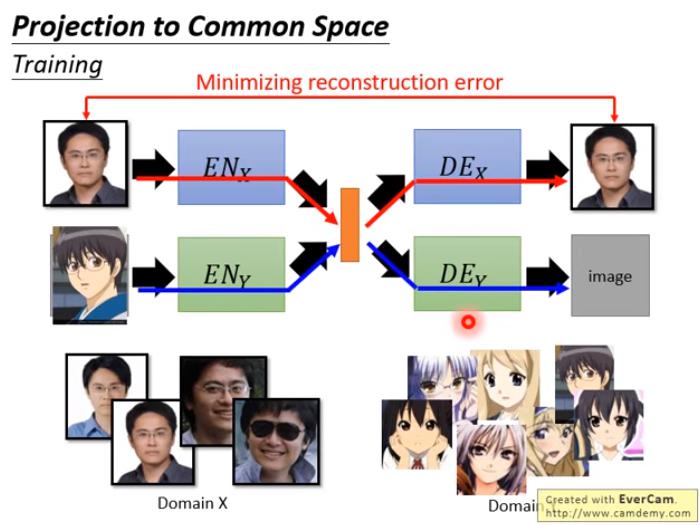 如果 decoder 後面加了 Discrminator 就像 VAE-GAN
如果 decoder 後面加了 Discrminator 就像 VAE-GAN
這樣的做法有些問題
- 上方的 autoencoder 和下方的 autoencoder 中間的 latent vector 是無關的
解法1: 兩邊的 encoder,最後幾層共享權重;兩邊的 decoder 前面幾層共享權重, encoder 共享權重的最極端狀況:共用整個 encoder,只有 input 差了一個數字,代表是哪個 domain 來的 例如
- Couple GAN
- UNIT
解法2:Domain Adversarial Training
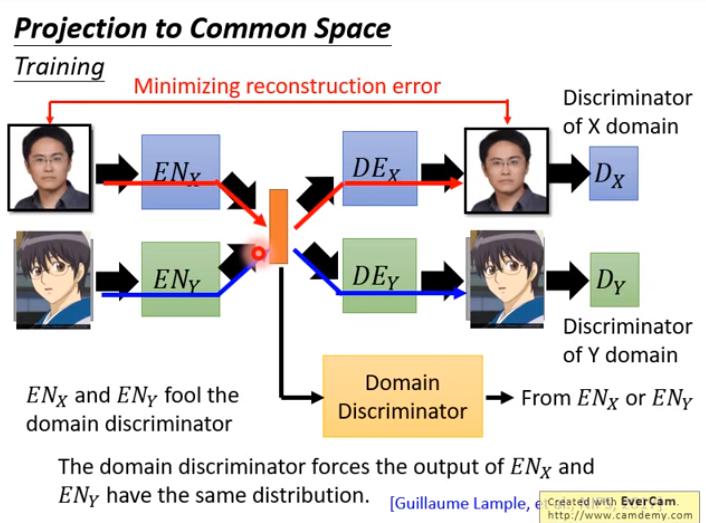
- 假設 兩個 domain 的 feature 分布一樣,較適合此作法,例如:
- domain A 和 B 的男女比、長短髮比、眼鏡與否比 一樣
解法3:Cycle-Consistency
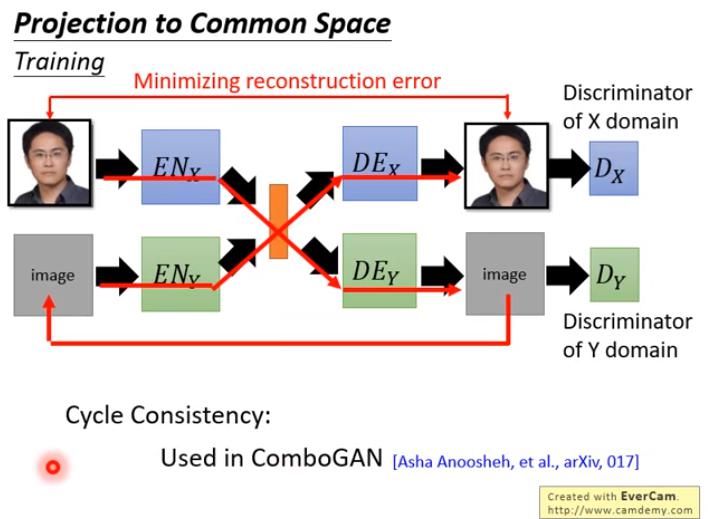
解法4:Semantic Consistency