Lecture 11 | Detection and Segmentation
補充:如何在訓練時 加入 hidden layer 論文:
- Net2Net, Ian Goodfellow
- Network Morphism, Microsoft
11.1 Segmentation
Other Computer Vision Tasks
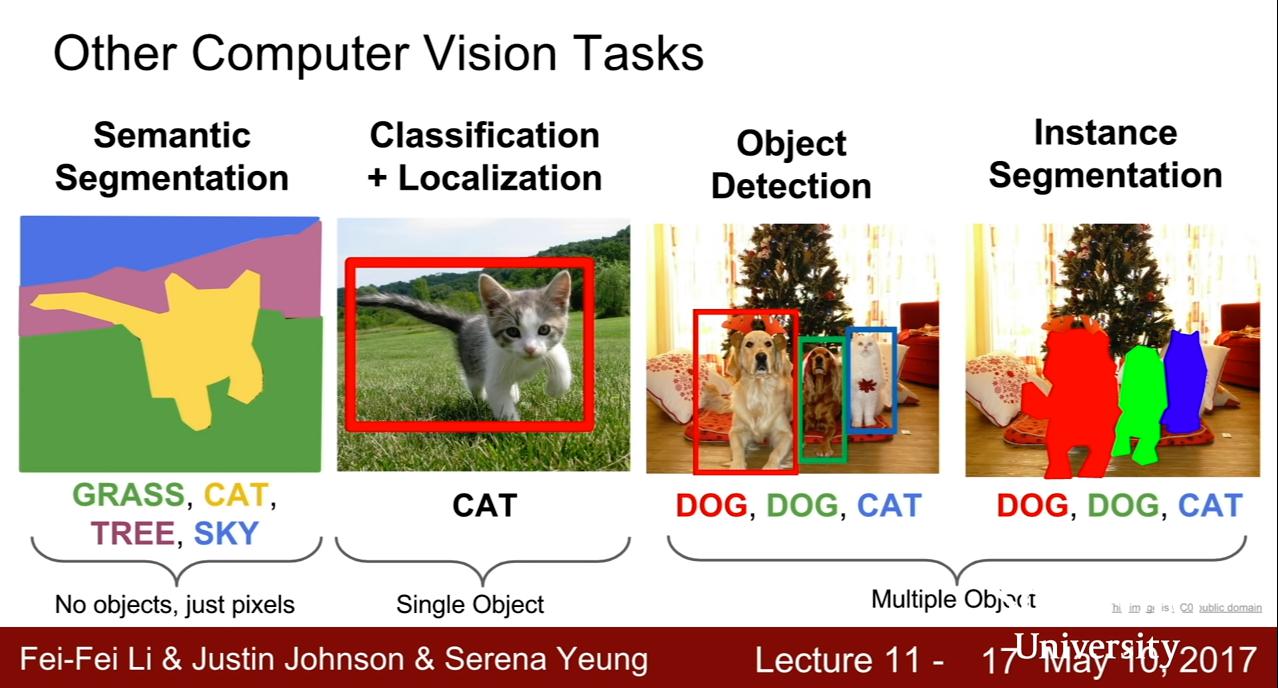
Semantic Segmentation
Fully Convolutional Network
- 全部 layer 都是卷積層
- zero padding,使每層 output 與原圖相同尺寸
(img 17:10)
- 但是全卷積的計算量太龐大了
- 因此會在 network 中做一些 downsampling 然後再 upsampling
- downsampling: 例如 maxpooling 或者 strided convolutions
- upsampling: 例如 unpooling 或者 transpose convolution
Unpooling
(img 18:58)
Max Unpooling
(img 20:26)
Transpose Convolution
- 這才真的在學習如何做 upsampling
- 別稱:deconvolution、fractionally-strided convolution、upconvolution、backwards strided convolution
(img 25:)
- 3x3 transpose convolution
- stride 2
- pad 1
11.2 Localization
11.3 Detection
Different from classification & localization,因為在 detection problem 中,一張圖可能有多個 object
用暴力法來抓 window 太耗時了,因此先使用 region proposal 給出一些可能的候選 region,然後再使用一般的 classification network 進行分類。
region proposal
- 更像是傳統的 computer vision 的方法,像是訊號處理、圖象處理等,給定輸入的圖片,region proposal network 會給出 object 可能存在的上千個框,傳統來說會偵測邊界,不過 network 會偵測點狀物?
- region proposal 有時又被稱為 Regions of Interest (ROI) ?
- 這樣跑起來很快
- 一個例子是 Selective Search,大約給出 2000 個 region
- 雖然框框可能很多 noise,不過 recall 很高
R-CNN
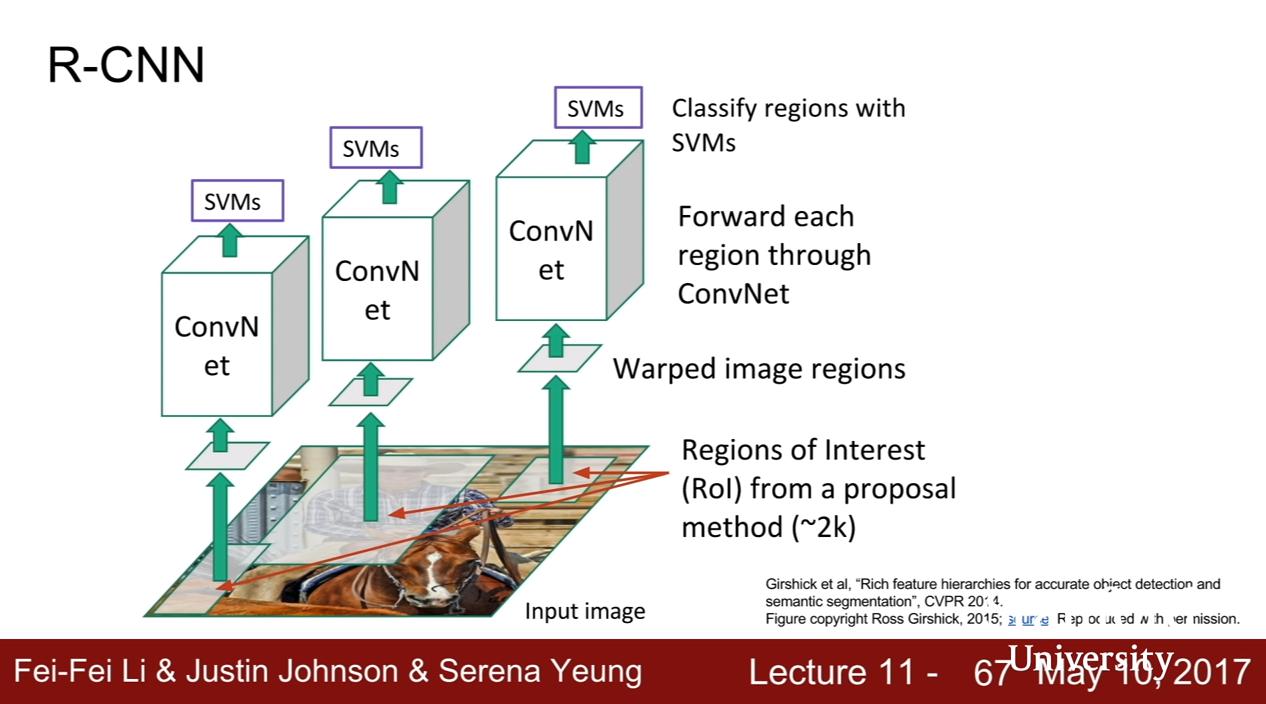
Girshick et al, "Rich feature hierarchies for accurate object detection and semantic segmentation", CVPR 2014
- Region Proposal Networks, 例如 Selective Search
- 並不是 learn 出來的,是固定的 algorithm
- 把挑出的 region proposals 調整為固定尺寸
- ConvNet (可以同時做 regression 以矯正 bounding boxes,投影片少了這頁解釋)
- SVMs 做分類 (why not use ConvNet???)
RCNN 自己也會用 regression 來輸出一些值以矯正 proposed bounding boxes,因為前面挑出的 proposal 可能並非完美
- 因此 loss function 是一個 multi-task loss
R-CNN: Problems

- Ad hoc (特設?) training objectives
- Fine-tune network with softmax classifier (log loss)
- Train post-hoc (事後) linear SVMs (hinge loss)
- Train post-hoc (事後) bounding-box regressions (least squares)
- Training is slow (84h), takes a lot of disk space
- Inference (detection) is slow
- 47s / image with VGG16
- Fixed by SPP-net
Fast R-CNN
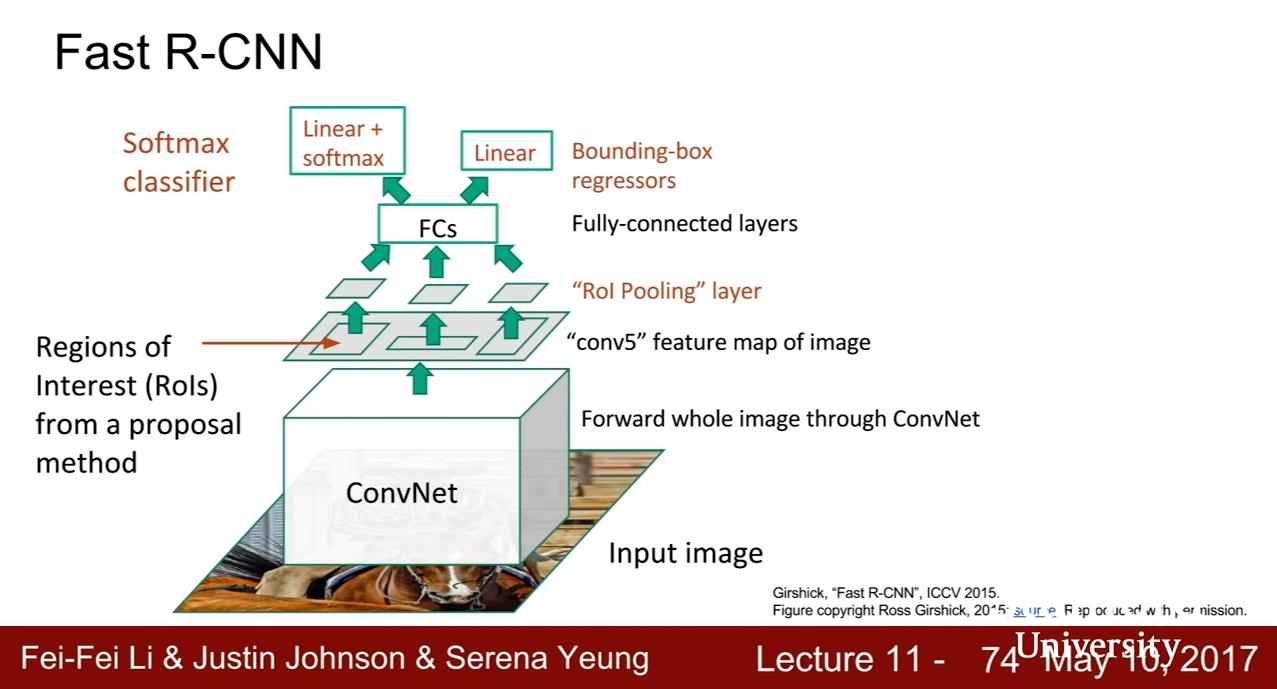
Girshick, "Fast R-CNN", ICCV 2015
- 不再用 ROI,而是通過一些 Conv 層,得到高解析度的 feature map
- 此時對 feature map 使用 region proposal (此時仍然是用固定的演算法像是 selective search,中文版應該翻錯了)
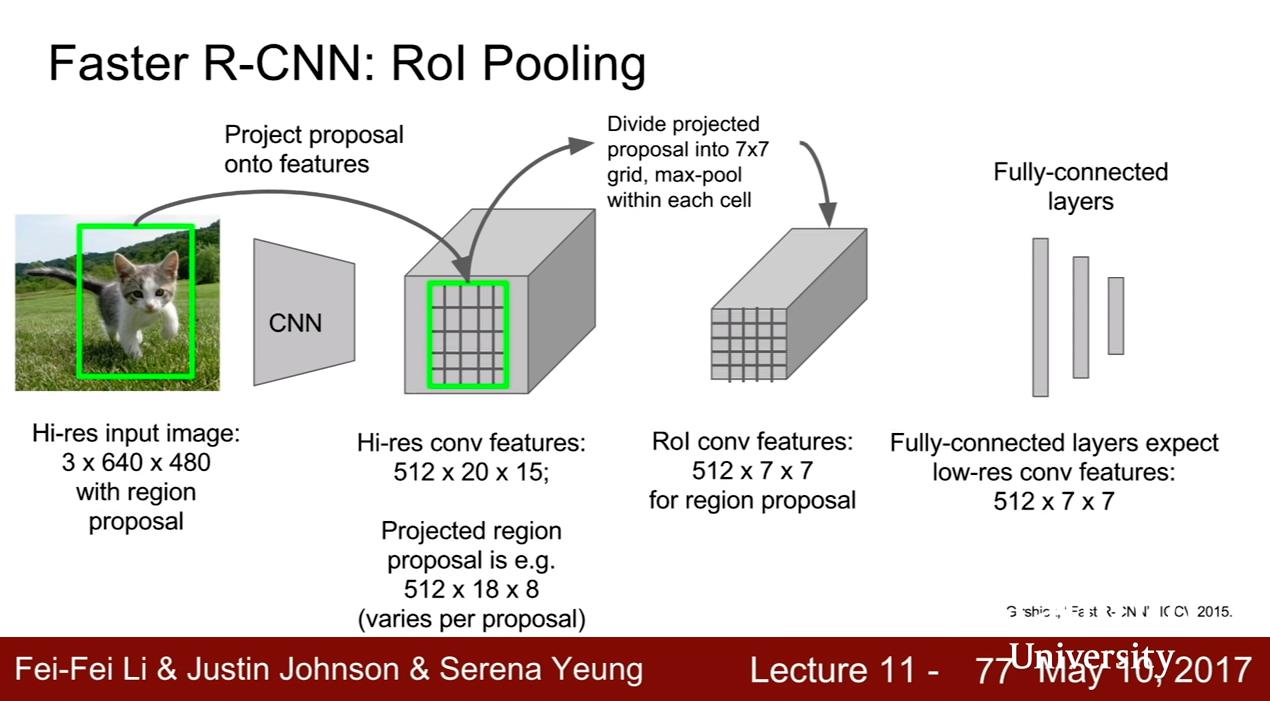
- ROI Pooling layer:用可微的方法將這些 ROI 重新統一尺寸,以輸入到後面的
- Fully-connected layers
- 接 Softmax 分類,以及 Bounding-box regressors 修正
Faster R-CNN? (X)
被跳過的細節,聽說就像 max-pooling?
R-CNN v.s. SPP v.s. Fast R-CNN
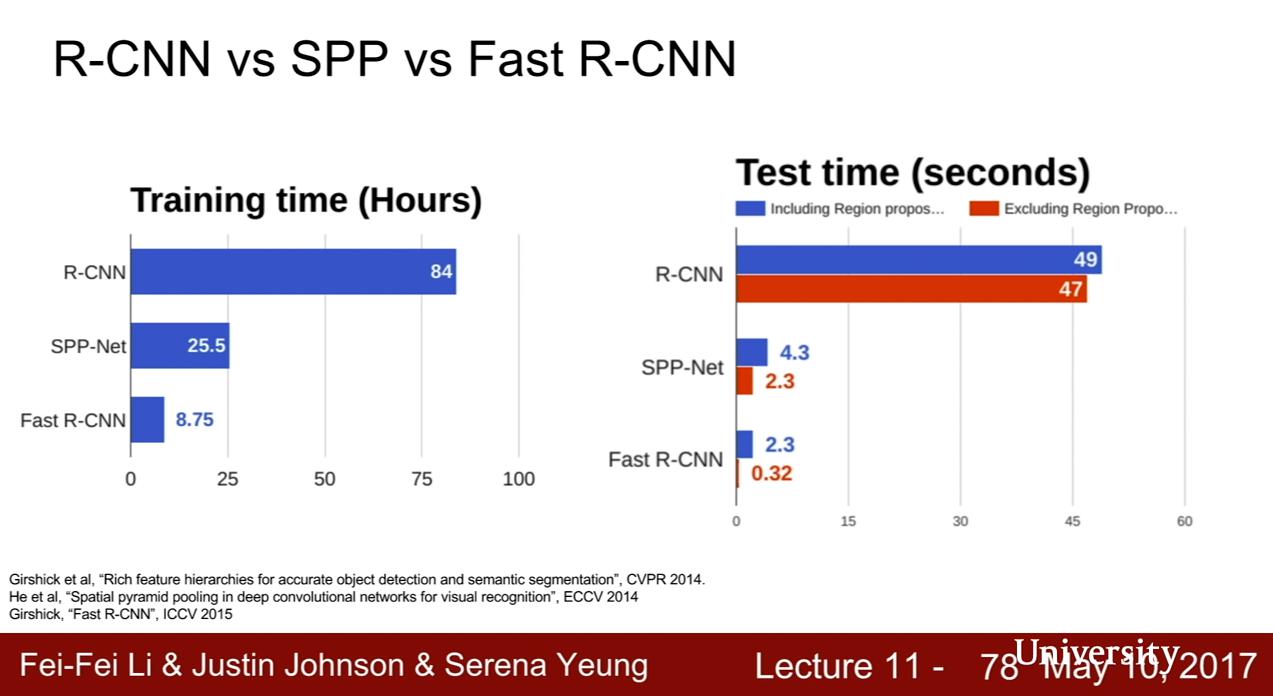
Fast R-CNN 訓練時間快了 10 倍,because we're sharing all this computation between different feature maps (沒懂)
- 把 ROIs 丟進 convolutional 計算只需要不到 1 秒
- 瓶頸在於 region proposal 速度
Faster R-CNN
Ren et al, "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks", NIPS 2015
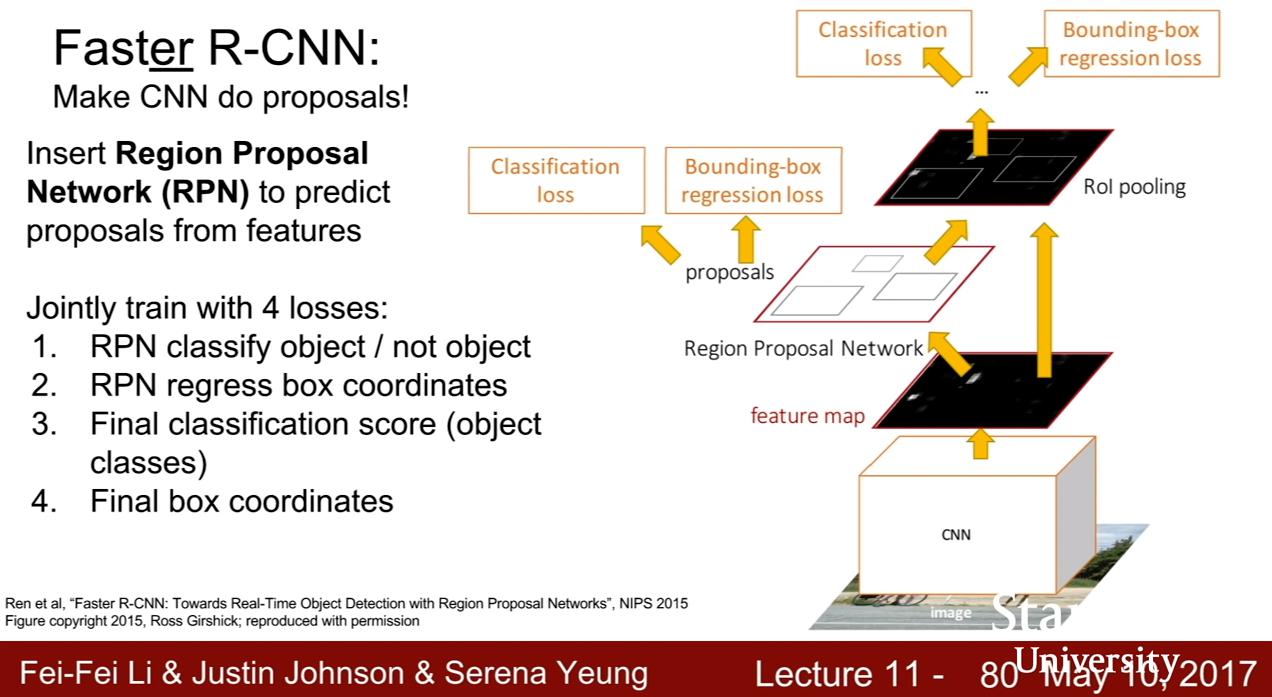
- 直接讓 CNN 來選 proposals!! 使用 Region Proposal Network (RPN) 從 feature map 來預測 proposals
Jointly train 4 個 losses
- RPN classify obj / not obj
- RPN regress box coord
- Final classification score (obj classes)
- Final box coordinates (同樣是 offset,用來修正前面 proposal 的錯誤)
為何 proposal 到 classification loss以及 bounding box regression 就不用先經過 ROI pooling???
Q&A
Q:如何給 RPN 的 proposal 正確或錯誤的 label? A:若重疊部分大於某個閾值,就判斷為正,否則判斷為負 (我猜是以 IoU 為判斷依據)
Detection without Proposals: YOLO / SSD
Redmon et al, "You Only Look Once: Unified, Real-Time Object Detection", CVPR 2016 Liu et al, "SSD: Single-Shot MultiBox Detector", ECCV 2016
Single Shot Detection?
Output:
- :grid size
- : # base bounding boxes (以圖上例子應該是 3,代表各種不同形狀的 bounding boxes?)
- : classification + bounding boxes
- :# classes
Object Detection: Losts of variables

Aside: Object Detection + Captioning = Dense Captioning

- 有點像 Fast R-CNN,只是最後接的不是 softmax 或 SVM,而是 RNN 的語言模型
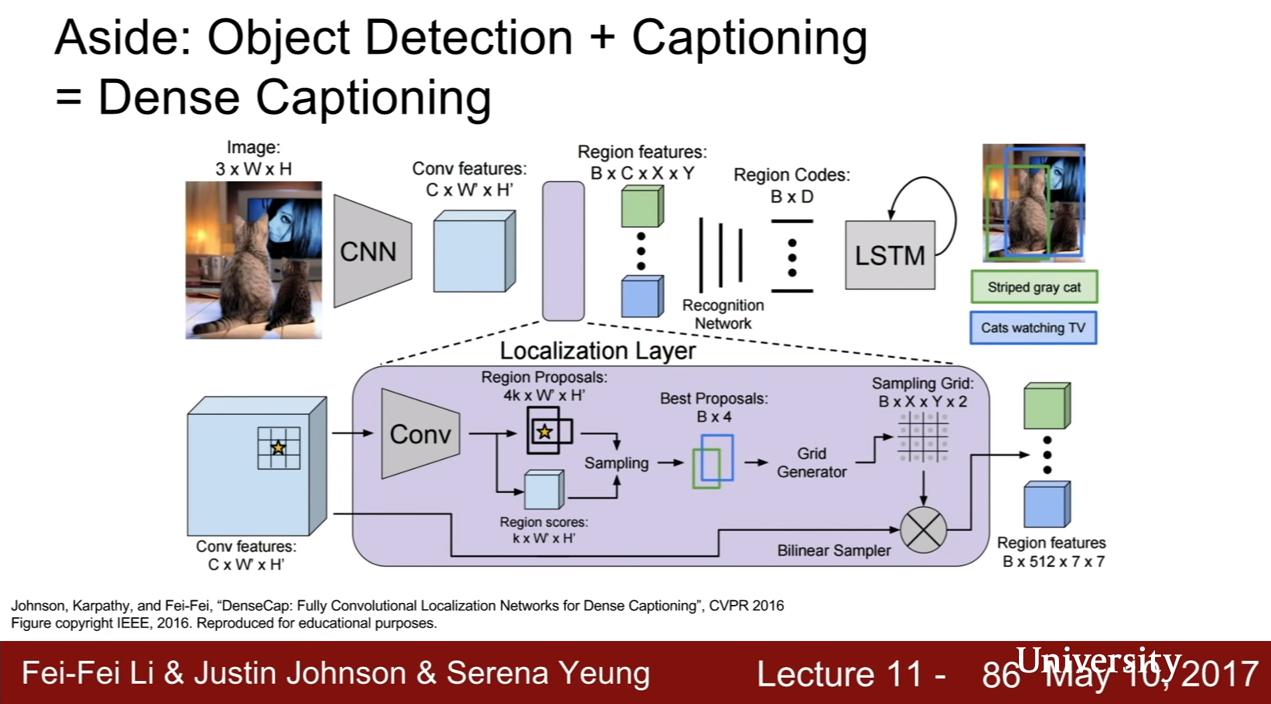
- 又一個沒空講的 slide
Instance Segmentation
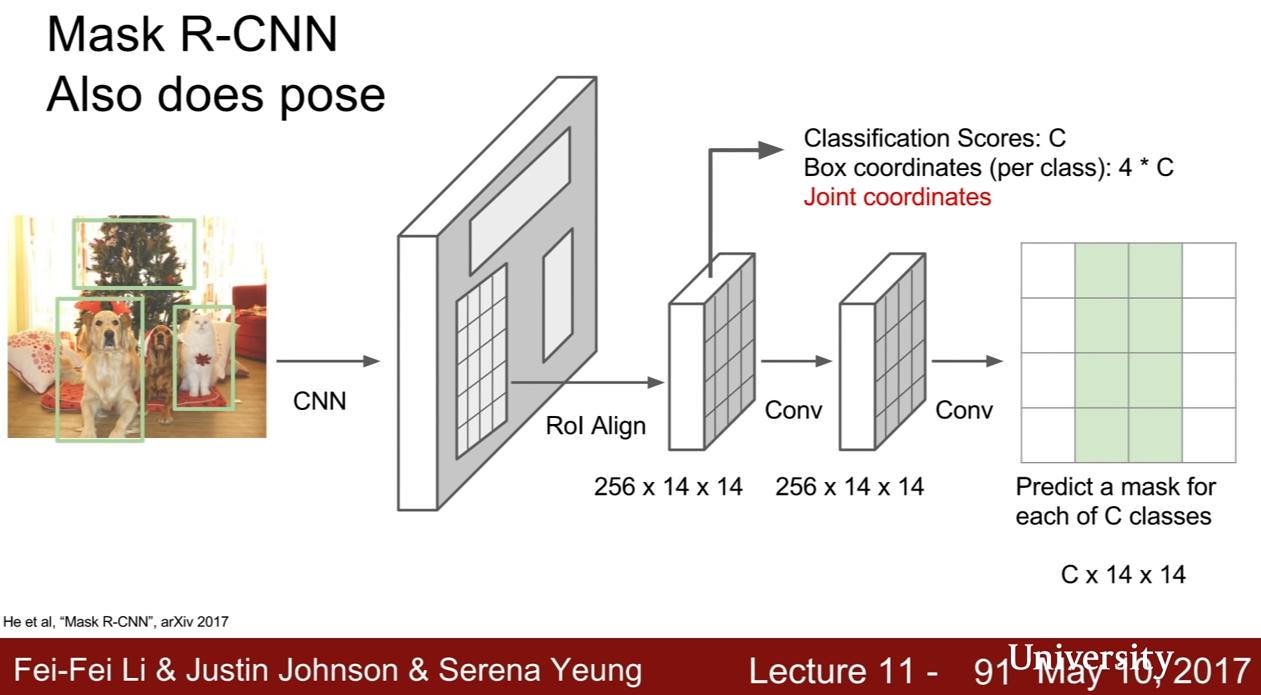
Mask R-CNN
He et al, "Mask R-CNN", 2017 和 Faster R-CNN 很像
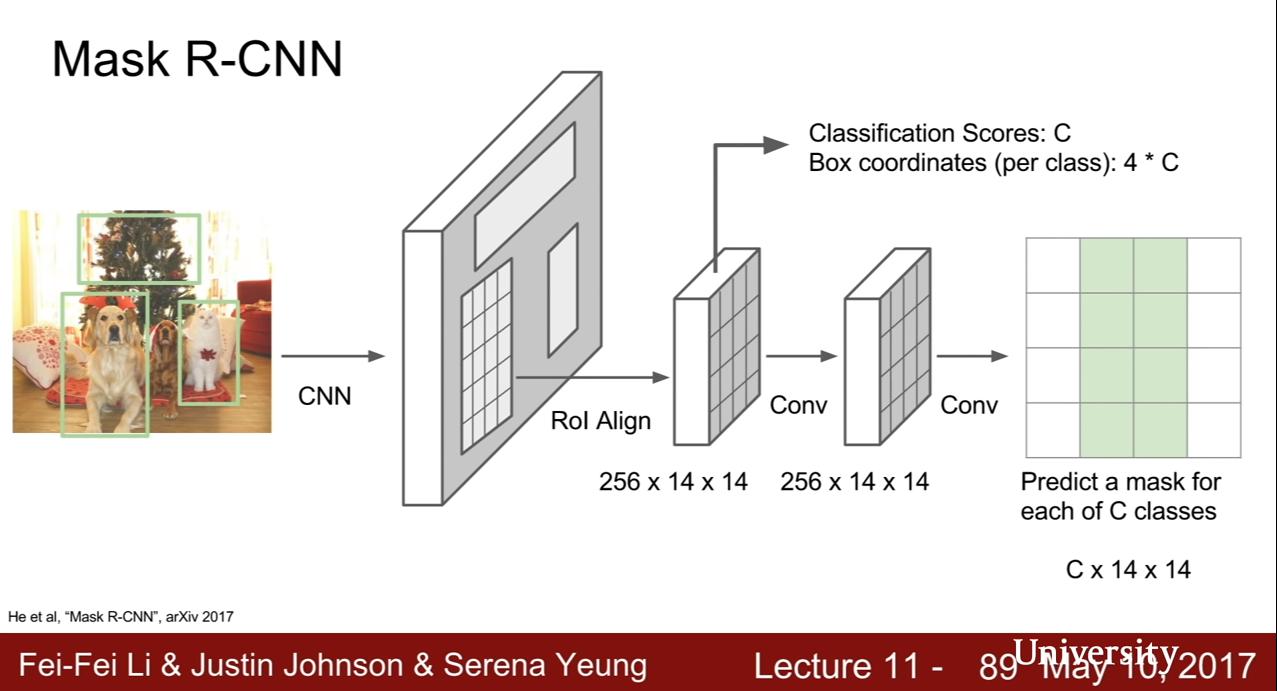
圖中一片一片應該是每個階段的 output
- ConvNet & Region Proposal Network
- RoI Align (目前都和 Faster R-CNN 很像),project into convolutional feature map,接下來有兩個分支 3-1. output classification + bounding box 3-2. 針對每個 Region Proposal 還做 semantic segmentation
Mask R-CNN also does pose estimation