
Value-based Approach - Learning a Critic
- A critic does not determine the action
- Given an actor , it evaluates how good the actor is
其中一種 critic: State value function
State value function
- When using actor , the cumulated reward expects to be obtained after seeing observation (state) s
- 給不同的 actor ,就算現在是同一個 state,那 V 也是不一樣的
如何評估
Monte-Carlo based approach

- critic 看這個 actor 玩很多場遊戲
- G 是 cumulated reward
- 訓練一個 model,input = state ,output = V(s),使得 V(s) 和 G 越接近越好。
- 其實 train 的方式跟一般的 regression 差不多
Temporal-difference approach

- 可能的解釋方式: 看到 會把她轉換成 和 ,因此 和 等價
- 訓練一個 model,input = ,output = 使得 和 越接近越好。
- 使用 temporal difference 的好處是,有些遊戲時間非常的長,不希望等到整場遊戲結束才能 train model,那使用 temporal difference 是可以隨著遊戲過程而更新 model 的。
MC vs TD (詳見 A3C 影片)

- Monte-Carlo based Approach
- unbiased estimation
- larger variance
- Temporal-Difference based Approach
- maybe biased
- smaller variance

- 使用 MC 會算出
- 使用 TD 會算出
- 因
- 又
- 不懂,我總覺得應該是因為 ,又
- DRL Lec3 有更正投影片了,是
- 那 0 (MC) 跟 3/4 (TD) 誰對呢?
- 若環境有 Markov 的特性(只受上一個狀態影響),則 TD 可能會估比較準,否則 MC 較準
- 為什麼呢? 只可意會,不可言傳
另一種 critic - Q function (State-action value function)
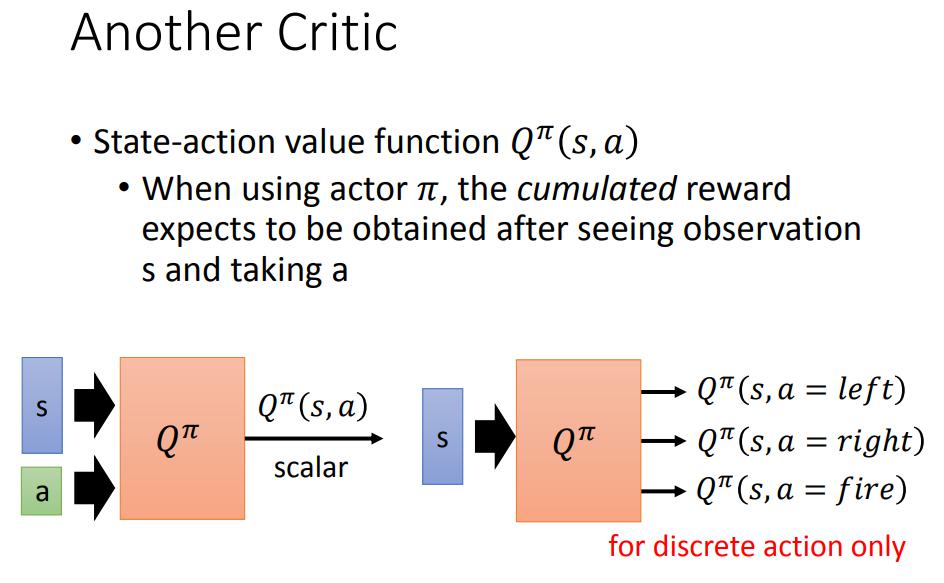 State-action value function
State-action value function
- 選定某個 actor ,看到某 state 且採取某 action 之後,期望得到的 cumulated reward
- 之前的 critic 並沒有看 action
- input 可能是 s 和 a,可以 output 出
- 改良的版本 input 是 s,直接 output 採取各種行動 a 所得到的
- 這個版本只適用於 discrete action
- 可以用 Q function 找出比較好的 actor
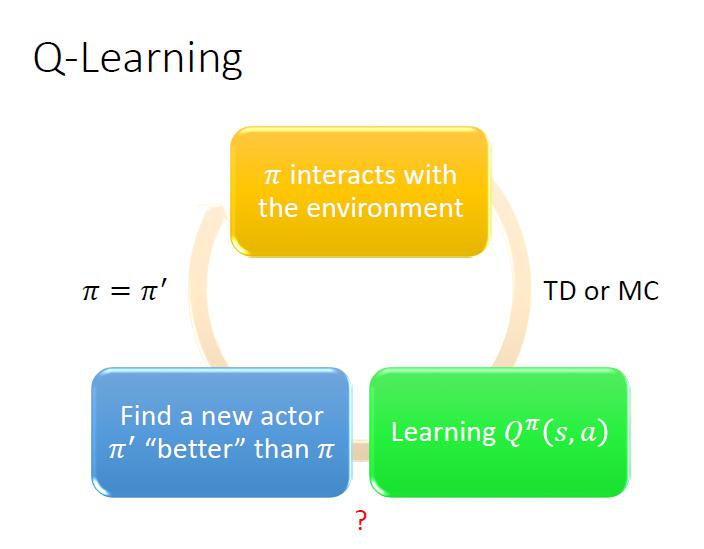
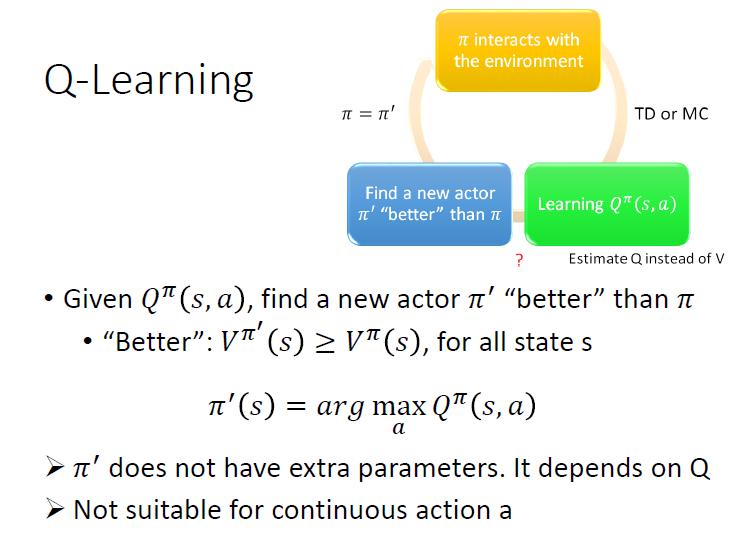
- 使用 Q function 找到一個 做得比 好
- 「做得比 好」的定義:對於所有 state ,
- 於是就需要解
論文:Rainbow: Combining Improvements in Deep Reinforcement Learning
- 七種不同的 DQN 的 trick
- Double DQN 跟 Dueling DQN 好像比較好實作
Actor - Critic
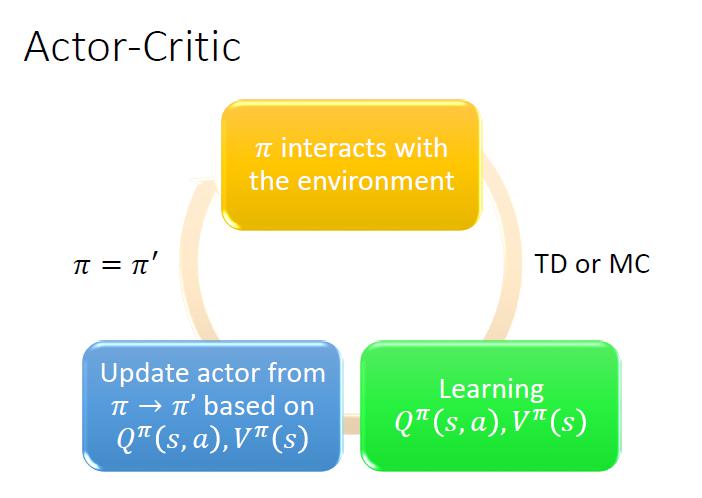
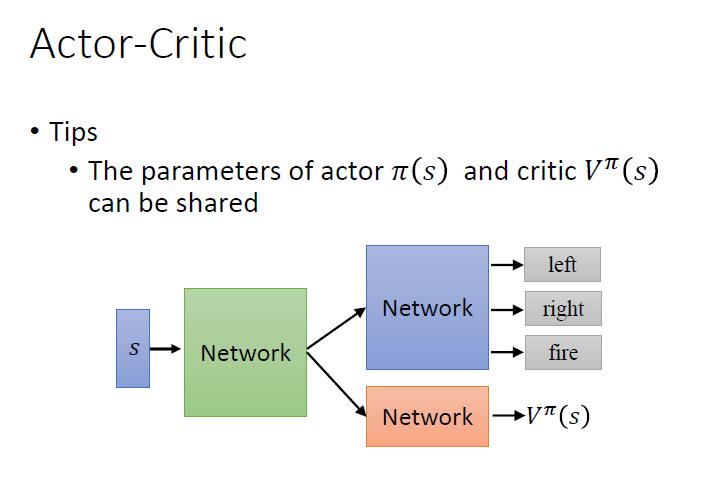
Actor 不跟 環境的 reward 學,只跟 critic 學
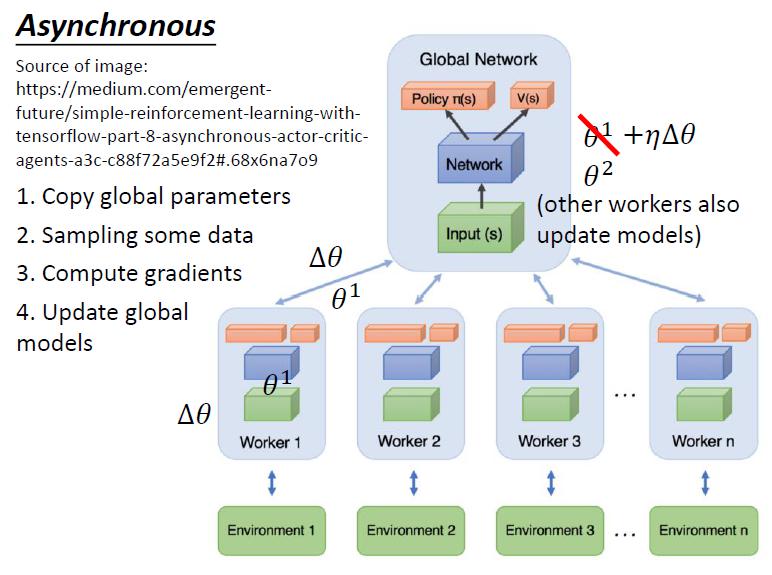
- 開分身來更新 weight
- 火影忍者
- 要開很多分身就要開很多台 machine
Pathwise Derivative Policy Gradient
- Actor - Critic 的一個變形
- 跟 GAN 很像
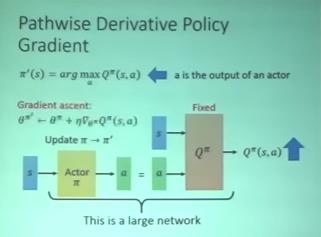 在 Q-learning 時,沒辦法處理 action 是 continuous 的 case。這時在 Q-learning 前面接一個 actor network ,input 是 s,output 是 a,目標是找到一個 a 讓 的值越大越好。
在 Q-learning 時,沒辦法處理 action 是 continuous 的 case。這時在 Q-learning 前面接一個 actor network ,input 是 s,output 是 a,目標是找到一個 a 讓 的值越大越好。
- 一個比較著名的方法是 DDPG
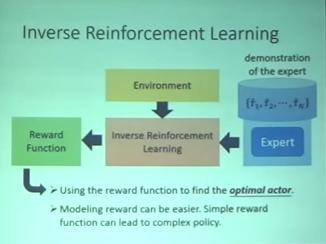
Inverse Reinforcement Learning
- 沒有 reward (因為有時候 reward 太難定)
- 有時候人訂的 reward 可能導致失控的結果
- 很多現實的任務我們根本不知道 reward function 長什麼樣子
- 只有專家的 demonstration
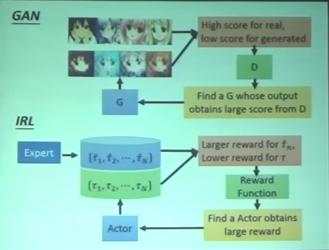
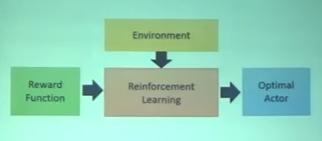
Reinforcement Learning 架構
Inverse Reinforcement Learning (IRL) 架構
IRL Framework
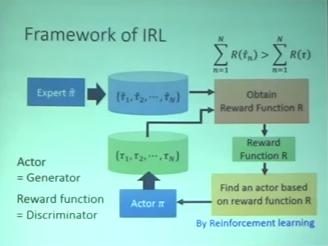
- Principle: The teacher is always the best.
- Basic idea:
- Initialize an actor
- In each iteration
- The actor interacts with the environments to obtain some trajectories
- Define a reward function, which makes the trajectories of the teacher better than the actor
- The actor learns to maximize the reward based on the new reward function.
- Output the reward function and the actor learned from the reward function
IRL 其實跟 GAN 的 process 一模一樣