Youtube
Q Learning 先參考 ML23-3 & AdvML_A3C
Tips
Exploration
Q-learning 的方式會導致 actor 只想採取得到最多 reward 的 action,而不採取其他行動,這是不好的,應該要鼓勵探索不同 action。

Replay Buffer
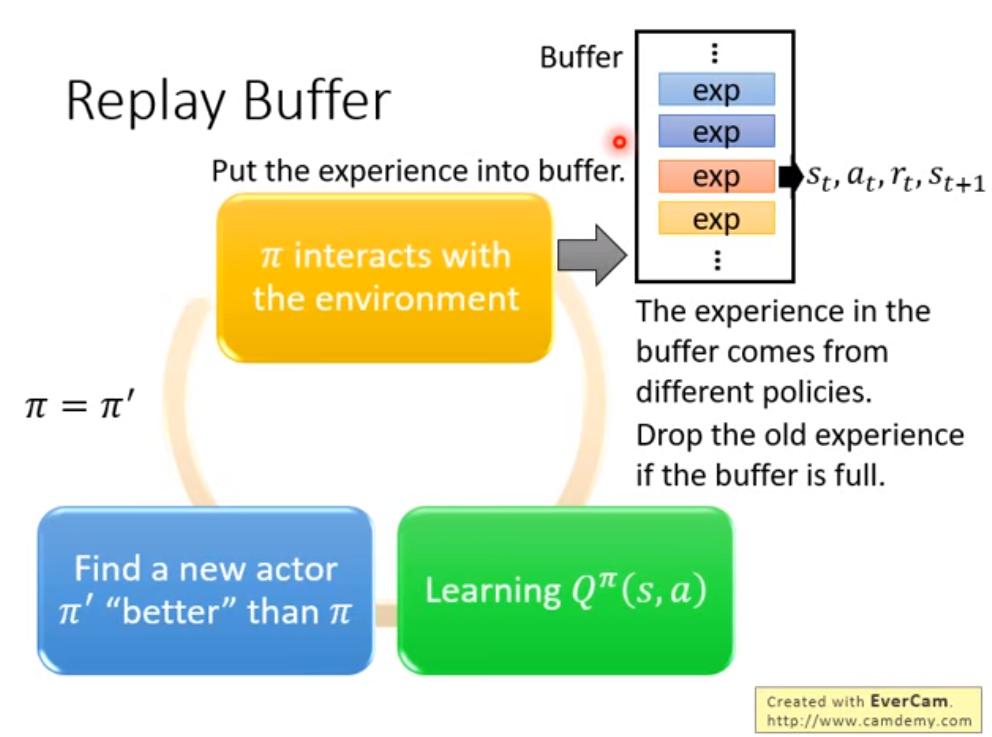 replay buffer 會存不同 actor 的 data。
replay buffer 會存不同 actor 的 data。
- In each iteration:
- Sample a batch
- Update Q-function
- 此時就變成了 Off-policy 的作法
- 和環境作互動的次數就可以減少
- 希望 batch 裡面的 data 越 diverse 越好
- 雖然評估的是 ,但是就算不是用 也沒關係,沒說為什麼
Typical Q-Learning Algorithm
