ML Lecture 5: Logistic Regression


 Logistic Regression
Logistic Regression
- 對 Class1 的定義是1,對 Class2 的定義是0
- 想要最大化 「 產生 training data的機率」,其實就等同於 「最小化 cross entropy」

為何 LR 的 loss 不用 Square Error


為何Generative Model 分類表現常常輸 Discriminative Model
Generative Model
- 有些假設存在(腦補)
- data量少時,很可能比discriminative model好,因為discriminative model的判斷依據幾乎來自data
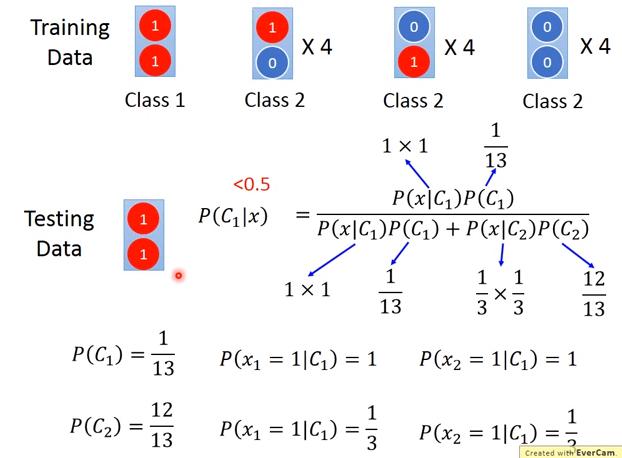
Generative Model: Naive Bayes

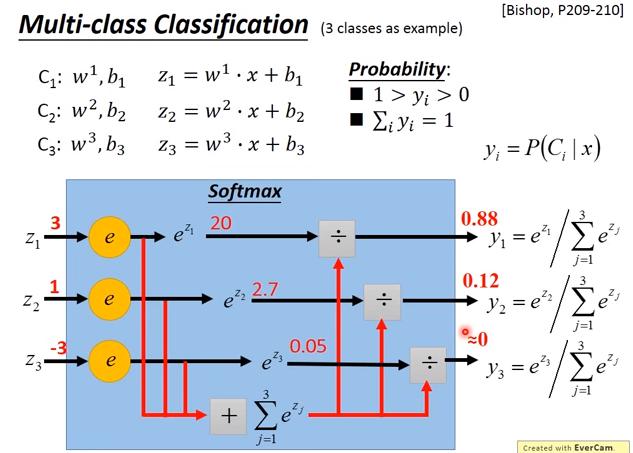
Multi-Class
softmax
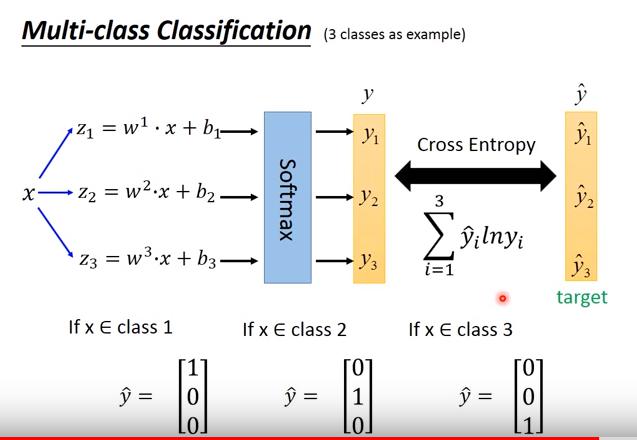
- 勘誤: Cross Entropy: