Youtube
Proximal Policy Optimization (PPO) 是 OpenAI 預設的 RL Algorithm
On-Policy -> Off-Policy
之前提到的 Policy Gradient 是 On-Policy 的做法,那為何需要 Off-Policy 呢?
- On-Policy 的做法每次更新 就要重新 sample 一次資料,因此訓練的時間大量消耗在 sampling 上,非常耗時。
- Off-Policy 希望可以用 來蒐集 data,用這些 data 來訓練 ,就可以用相同的 data 來 update 很多次 。
以下先介紹 importance sampling
Importance Sampling
從 p 這個 distribution 得到 x,要如何近似 f(x) 的期望值?
- 這個作法是我們有辦法從 p 這個 distribution 裡 sample 出 x 時的作法,實際情況我們無法直接 sample,只能從 q 這個 distribution 做 sampling,原因稍後會說明
從 q 這個 distribution 去 sample x 的作法
- 此時理論上 q 可以是任何 distribution,唯一限制是 q(x) 機率為0 時,p(x) 機率必定為 0 即可使用 importance sampling 的技巧。
然而實際上 p 和 q 的 distribution 不能差太多,為什麼?

- 雖然 從 p 和 q sample 出來的方式 期望值會相同,但是 VAR 會不同 (不太懂 VAR 不同又怎樣)
- 這段沒很懂,之後再重看
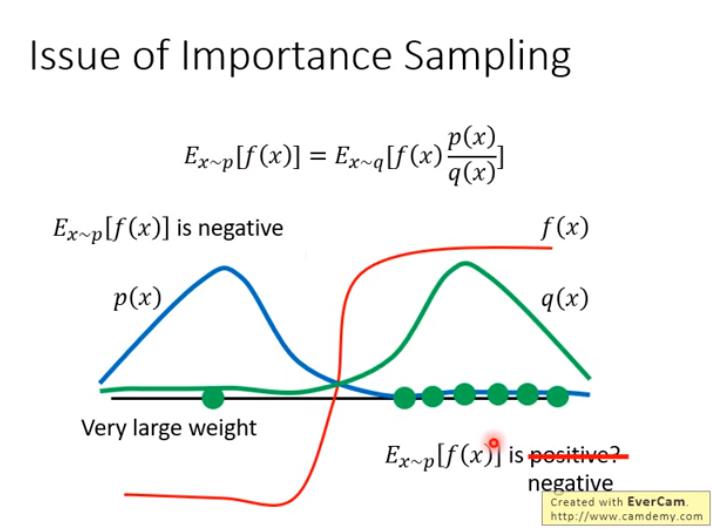 以上圖為例:
以上圖為例:
- 若 p 和 q 差很多,sampling 的時候,可能只 sample 到 q(x) 機率很大的 x (然而 p(x) 很小),而導致認為 會是正的
- 解決的方法:
- sample 夠多的點,才能真正近似
- 讓 p 和 q 不要差太多
On-policy -> Off-policy (with Importance Sampling)
 用 做示範(和環境互動),讓 學習
用 做示範(和環境互動),讓 學習
- 根據 importance sampling,
 老師表示:為了方便說明,在數學的部分做了大量簡化,這裡的講法並不嚴謹
老師表示:為了方便說明,在數學的部分做了大量簡化,這裡的講法並不嚴謹
- 本來應該使用 ,這裡使用 做近似
- 這裡也假設 和 是幾乎相同的
- 最終得到 以 做 demonstration,來更新 的 gradient
Review: 從 On-policy 改成 Off-policy 是使用 importance sampling 的技巧,因此若 和 差太多的話這招實務上就不奏效,那該如何避免它們差太多?
PPO / TRPO

- PPO 的前身是 TRPO,效果差不多,PPO較易實作
- 我覺得這個方程式的減號應該是加號? 要複習一下 KL divergence 了
- 量測的分布其實是指 和
PPO algorithm

- 和 policy gradient 不同的地方是,本來每個 iteration 只能更新一次 ,現在可以更新很多次
PPO2
- 這個方法非常好 implement
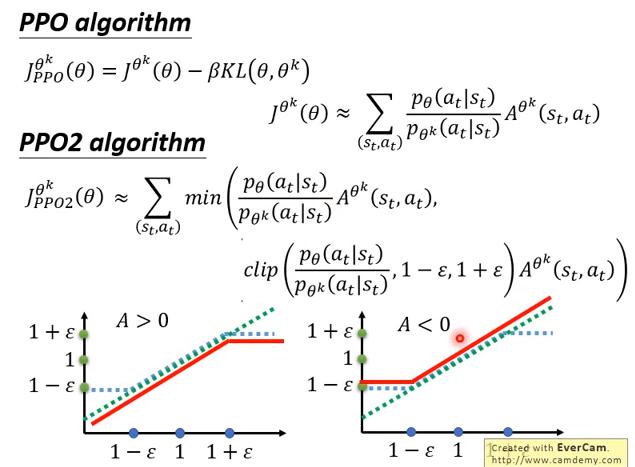
簡寫
- 橫軸是 ,縱軸是 (決定A的係數的?)輸出
- 綠線: (identity function)
- 藍線:
- 是一個可以調整的 hyperparameter (設0.1、0.2之類)
當 A大於0 時,取 min 後的輸出會是左圖的紅線;A小於0 時,取 min 後的輸出會是右圖的紅線,而這也很直觀,因為我們不希望 和 差太多,因此在 A大於0 時,雖然希望他調高 的機率,但又不希望他調高太多;反之 A小於0 時亦然。