Conditional Generation by RNN & Attention
Generating a structured object component-by-component
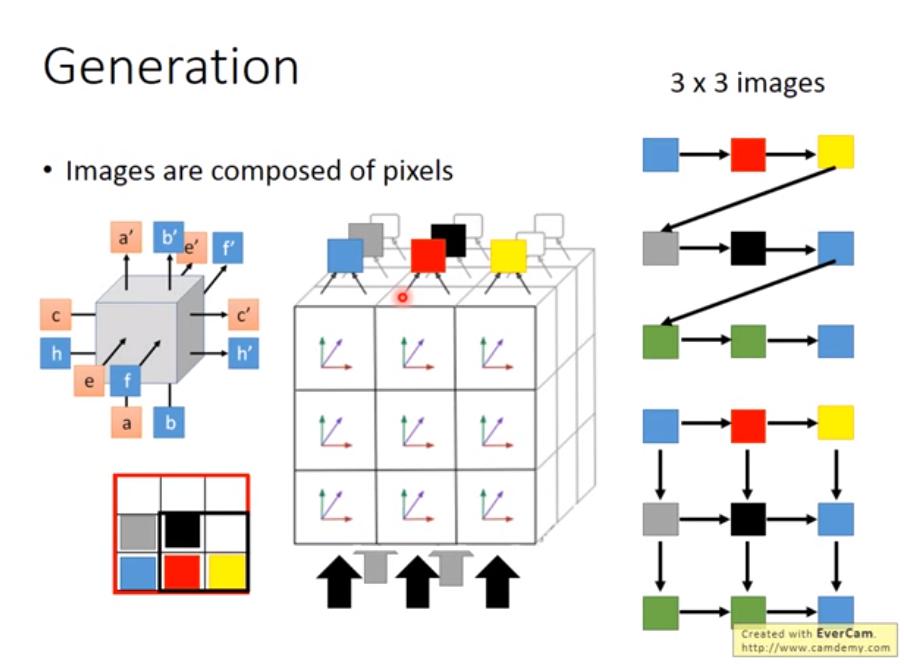 參考 3D Grid LSTM
參考 3D Grid LSTM

Image Caption Generation
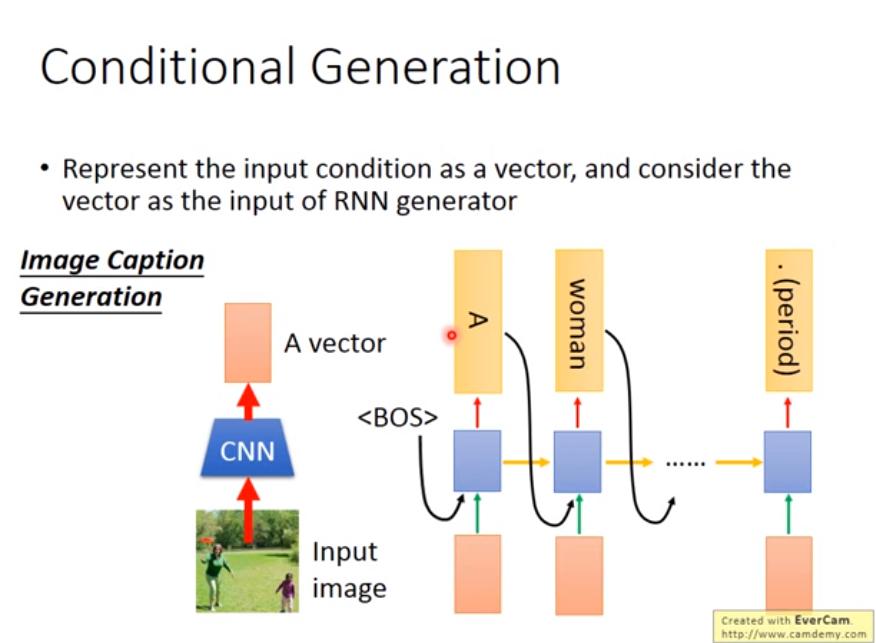
- 只將 CNN vector 輸入第一個 RNN step,RNN 之後有可能會忘記該圖長什麼樣子,一個 solution 是,每個 step 都 input 相同的 CNN vector
Machine Translation: seq2seq
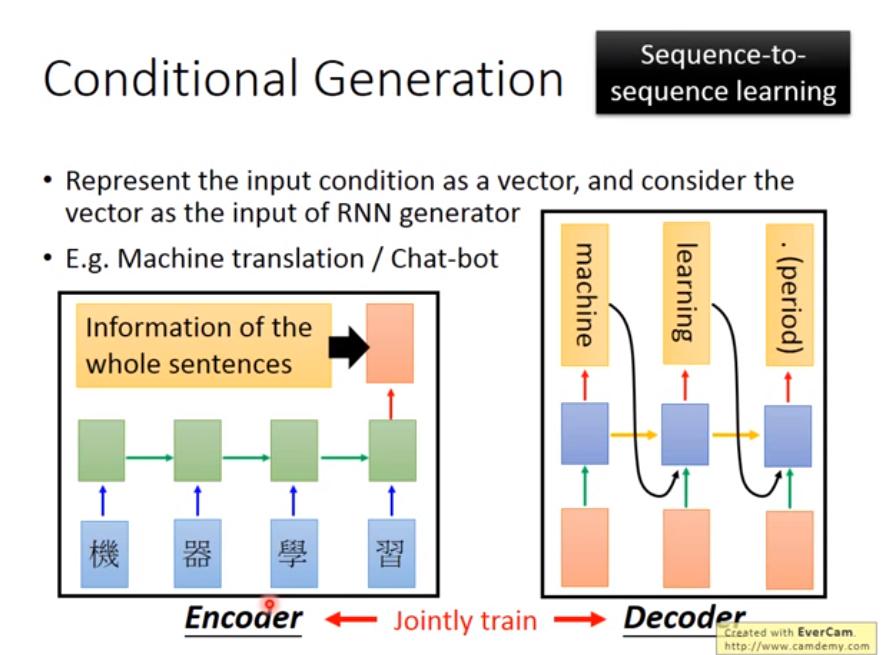
- 可以用和 Image Caption Generation 相同的方式
- Encoder 和 Decoder 的參數可以一樣,可以不一樣
- 參數一樣比較不容易 overfitting,資料多的時候也可以不一樣
Chat-bot: Conditional Generation (Hierarchical)
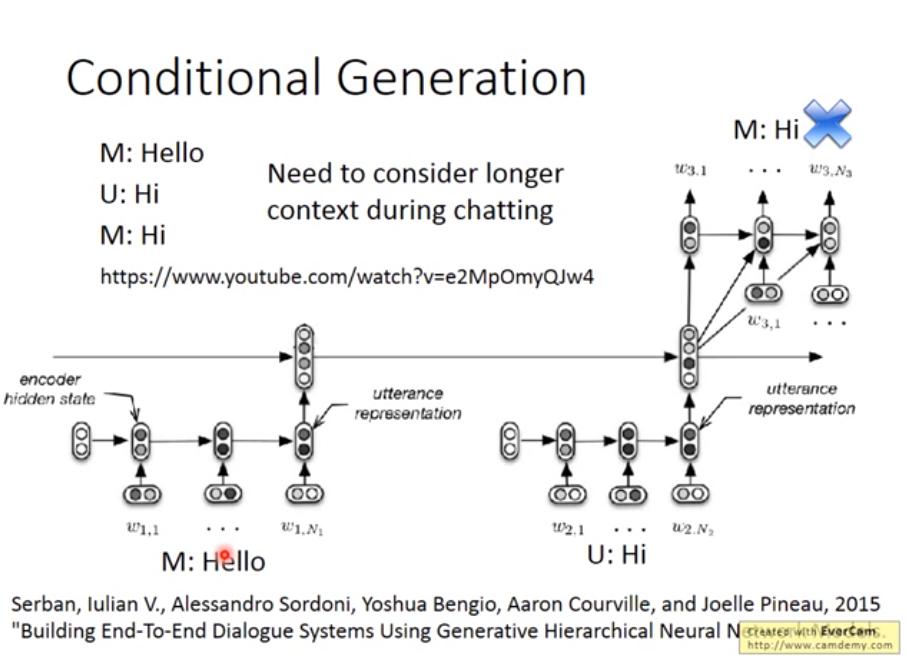
論文:Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models
Dynamic Conditional Generation
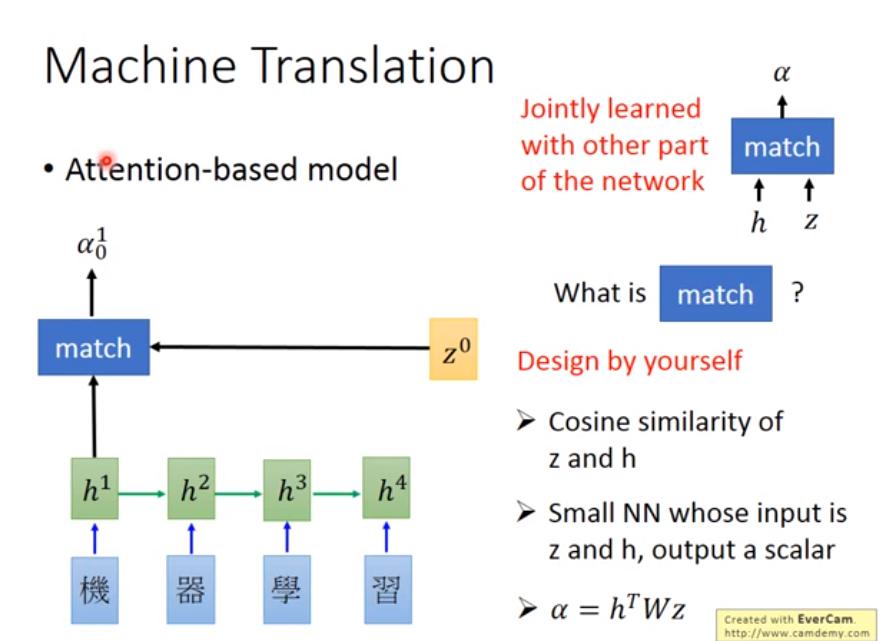
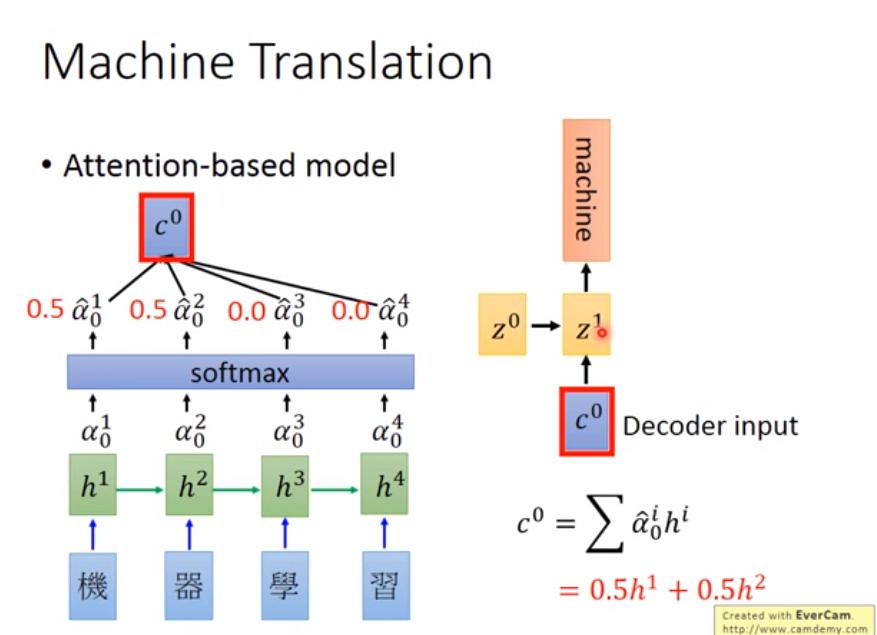
Attention (Dynamic Conditional Generation)
example
- 希望翻譯 "機器學習" 的時候, "machine" 只需要參考 "機器" 這個詞,而不是整個句子的 encoding 向量。
Speech Recognition
- 隨意看過去
Image Caption + Attention-based model
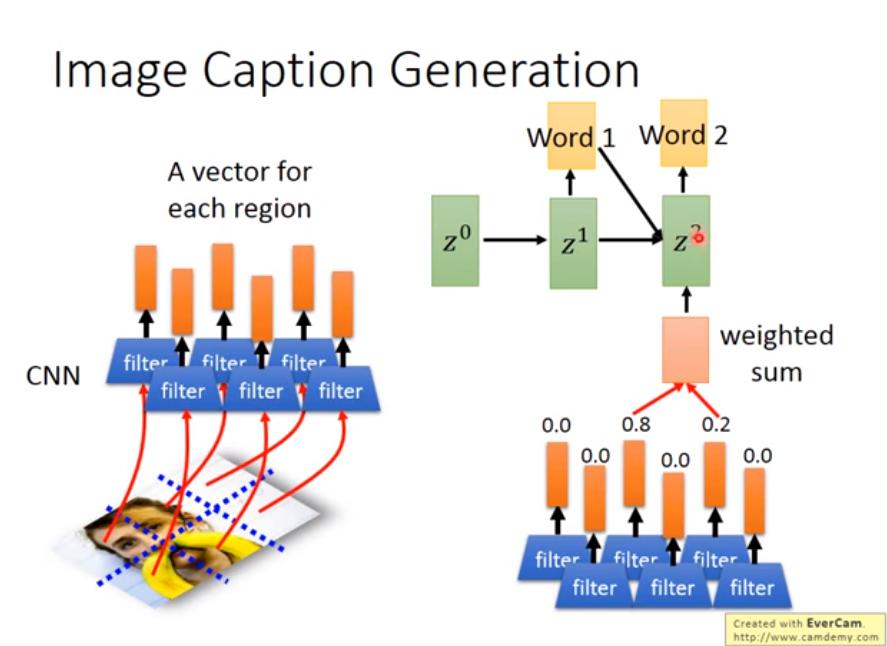
- 將 CNN 在 flatten 之前的 vector 取出來,做 attention
- 論文:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- 而且這樣 model 具備一定的可解釋性
Video
Memory Network
- 最早的應用:給 machine 看一個 document,然後問它一個問題,讓它 generate 答案。

- Document 以很多句子 的 vector 表示
- Query (question?) 也用一個 vector 表示
- 用 query vector 來對每個句子算 match score
- 然後用 match score 對每個句子做 weighted sum,作為 extracted information
- 最後把 query vector 跟 extracted information 一起丟進 DNN 就得到答案
- 整個 network 可以 jointly trained,包括
- 把 document 轉成句子 vector 的 network
- 把 query 轉成 vector 的 network
- 把 extracted information 轉成答案的 network ... 等
更複雜版本的 memory network
 算 match score 用的 vector 不一定要跟表示句子的 vector 一樣,不一樣其實可以得到更好的 performance
算 match score 用的 vector 不一定要跟表示句子的 vector 一樣,不一樣其實可以得到更好的 performance
- 用 表示 document 句子,並和 計算 extracted information
- 用 和 一起計算 match score
- 這個影片提到, 其實就像 hash table 裡面的 key (可以想像成,key 是要算 attention 的 weight,因為要用這個資訊來「找」value,故名 key), 就像 hash table 裡面的 value
另外會跑很多個循環去把計算出的 extracted information 跟 query 加在一起重新計算 match score,然後又再算出一次 extracted information,就像反覆思考一樣,這叫做 hopping。
 上圖為 hopping 的另一種看法
上圖為 hopping 的另一種看法
- 4個 embedding matrix 可以一樣可以不一樣
- 可以把上圖看成 2 個 layer 的 network
這個影片的 18 分處,具體去看 hopping 是怎麼思考的: (img 18:00)
ReasoNet
而 multiple hop 到底需要多少次 hop?
- 讓 machine 自己學
- arXiv 1609.05284
memory network + attention 可以使用 tree-structure,有點複雜,跳過

Visual Question Answering 原理跟 memory network 差不多
Neural Turing Machine
剛剛的 memory network 是在 memory 裡面做 attention,並從 memory 萃取出 information。而 Neural Turing Machine 還可以根據 match score 去修改 memory 中的內容。

- 初始 memory sequence 的第 i 個 vector
- 第 i 個 vector 初始的 attention weight
- 初始的 extracted information
- 可以是 NN,會 output
- 用 一起計算出 match score 得到 ,然後 softmax,得到新的 attention ,計算 match score 的流程如下圖

- 的作用分別是把之前的 memory 清空(erase),以及 寫入新的 memory,如下圖

- e 的每個 dimension 的 output 都介於 0~1 之間
- 就是新的 memory
- 用 一起計算出 match score 得到 ,然後 softmax,得到新的 attention ,計算 match score 的流程如下圖
於是 Neural Turing Machine 的整體架構如下圖

Tips for Generation
Video to Text with Attention

- :產生第 t 個詞時,對第 i 個 component (這裡是影片的 frame)的 attention
- 不好的 Attention
- 很多 都 attend 集中在某個 frame
- 好的 Attention
- 對於每個 component (影片中的每個 frame) 都有一定的 attention
- 因此可以對 Attention 做 regularization,例子:
- regularization term:, 是可調整的 hyperparameter
- 可自定義
Mismatch between Train and Test

- training 時,RNN 每個 step 的 input 都是正確答案 (reference)

- 然而 testing 時,RNN 每個 step 的 input 是它上個 step 的 output (from model)
 這又稱為 Exposure Bias
這又稱為 Exposure Bias

- 如果把 training 的 process 改成:把上個 step 的 output 當成下個 step 的 input,聽起來似乎很合理
- 不過實務上 train 不起來,有個解法叫 Scheduled Sampling
Scheduled Sampling

- 到底每個 step 應該要看 reference 還是 model output 呢?
- 都給他們一個機率
- 一開始只看 reference,到後來只看 model output
- 三種 decay 方法似乎沒有明顯哪種比較好,自己實驗ㄅ
- 實驗結果 論文:Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
Beam Search
在吳恩達 Deep Learning Specialization 上過了,不多贅述
Better Idea?
之前 Scheduled Sampling 要解決的 problem 為何不直接把 RNN 每個 step 的 output distribution 當作下一個 step 的 input 就好了呢? 很多好處啊
- training 的時候可以直接 BP 到上一個 step
- testing 的時候可以不用考慮多個 path,也不用做 beam search 了,直接 output distribution
 老師直覺這個做法會變糟,原因如下:
老師直覺這個做法會變糟,原因如下:
- 下個 step 要 output 什麼 word 應該要完全 depends on 上個 word
- 不過還是可以實驗看看會發生啥事
Object level v.s. Component level
如果使用 Object level 的 criterion ,來衡量「整個句子」寫得好不好,會是一個更佳的 objective function
- 但是使用這樣的 objective function 是沒辦法做 gradient descent 的,因為
- 看的是 RNN 的 hard output,即使 word 的機率有改變,只要最終 output 的 一樣,那 就不會變,也就是 gradient 會是 0。
- 而本來的 objective function (word-wise cross entropy?) 在微調參數的時候,是會變的,所以可以做 GD
- 那要怎麼辦呢?
- Reinforcement Learning
Reinforcement Learning

- RL 的 reward,基本只有最後才會拿到,可以用這招來 maximize 我們的 object level criterion
- 論文:Sequence Level Training with Recurrent Neural Networks. ICLR 2016
各方法比較

- 縱軸:和 XENT 相比的 performance
- XENT:使用傳統的 RNN language model 做的方法
- E2E:很像是前面【Better Idea?】說的方法,的確稍微差
- MIXER:RL 的方法

- 橫軸:Beam Size
- MIXER k:RL 的 Beam Size