為了考驗 generator 是不是單純把 training data 記下來(overfitting?),會將 input 做內插,看結果

Structured Learning 例子


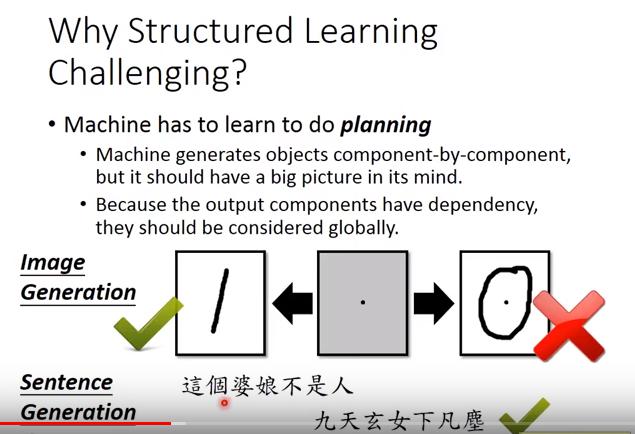
Why Structured Learning Challenging?

影片45分左右 Q&A 聽不太清楚
auto-encoder 少了什麼?
我們希望 generator 犯一點小錯,而不是單純複製出 data base 的圖片,這樣才能 generalize。但是什麼樣的小錯是可以被允許的?
- auto-encoder 原先 pixel-wise 的 evaluation 方式沒辦法指出,哪裡多畫一個點或少畫一個點是嚴重或者輕微的。
auto-encoder 不會考慮 pixel 之間的關係 (correlation)
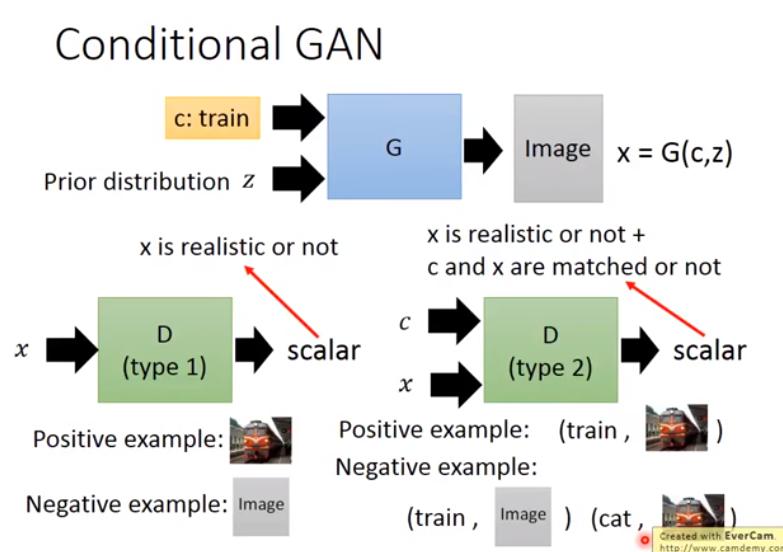
Conditional Generation

- 首先我們先得到一些有 attribute(髮長、性別等) 的圖片,並用圖片 learn 好一個 GAN
- 但是我們並不知道什麼樣的 input vector 會產生什麼樣的圖片(長髮/短髮, 男性/女性...)
- 因此可以使用類似 Autoencoder 的架構,將訓練好的 Generator 當作 Decoder,去訓練一個Encoder,使得 input 與 output 越像越好
- learn好 Encoder之後,每張圖片經過 Encoder 都會生成一個 vector z
- 我們將所有短髮圖片的 vector 平均會得到一個短髮 vector ,將所有長髮圖片的vector平均會得到一個長髮的vector
- 計算 會得到將短髮轉為長髮的向量v
- 若想將某張圖片從短髮變長髮,則先經過 encoder 產生z,然後使用 z+v 作為 generator的輸入,即可轉為長髮