Deep L-layer Neural network
Forward Propagation in a Deep Network
- 我們可以將input layer的x視為 , 即第0層的輸出
- 於是向量化後
for l in range(0,L): # 對於每層神經網路 Z[l] = np.dot(W[l],A[l-1] + b[l] A[l] = g_l(Z) #g_l為第l層的激活函數
Getting your matrix dimensions right
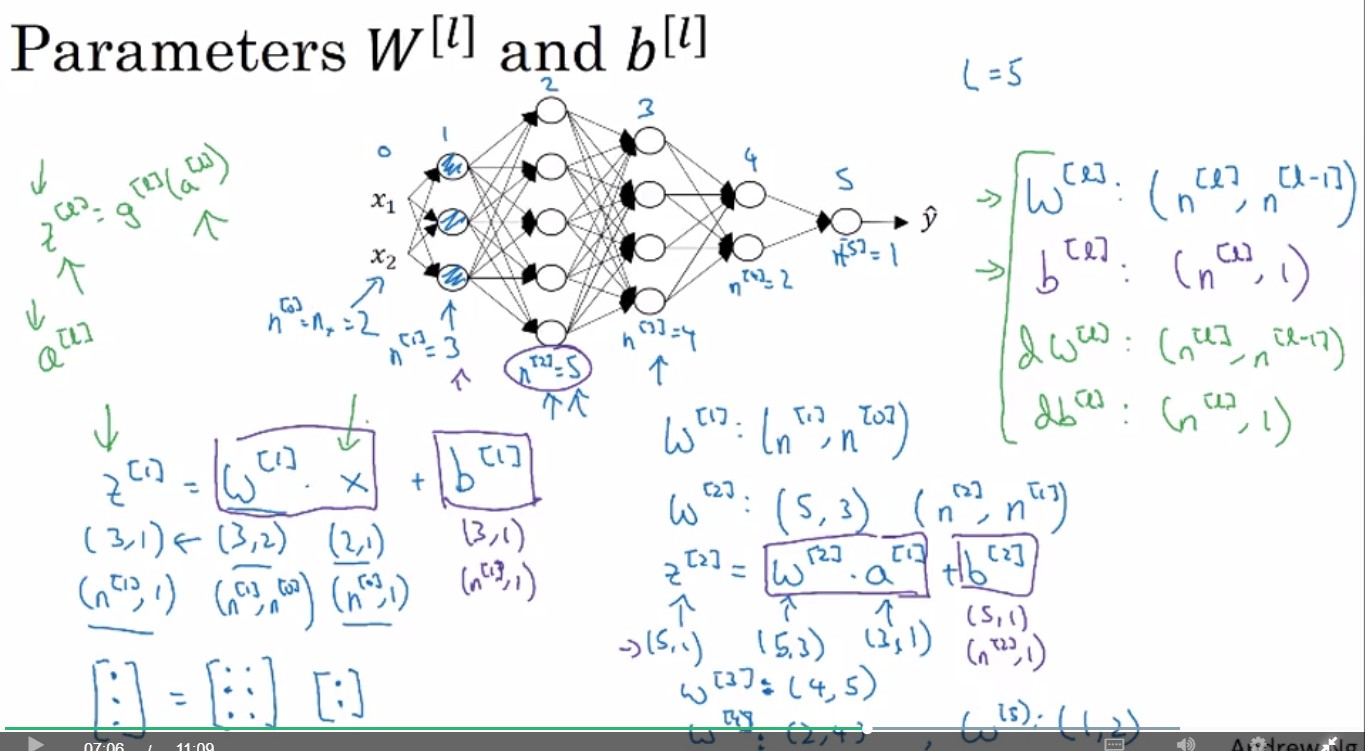 左上z跟a寫反了ㄅ???
左上z跟a寫反了ㄅ???
Review:
寫Python向量化後,各矩陣維度
- : (,)
- : (, 1)
- : (, 1)
- : (, 1)
知道這些能幫助自己在寫code時確認變數的dimension是否無誤。
(以下理解好像哪裡怪怪的要重看影片)
然而以上為data只有一筆的狀況。假設data有m筆
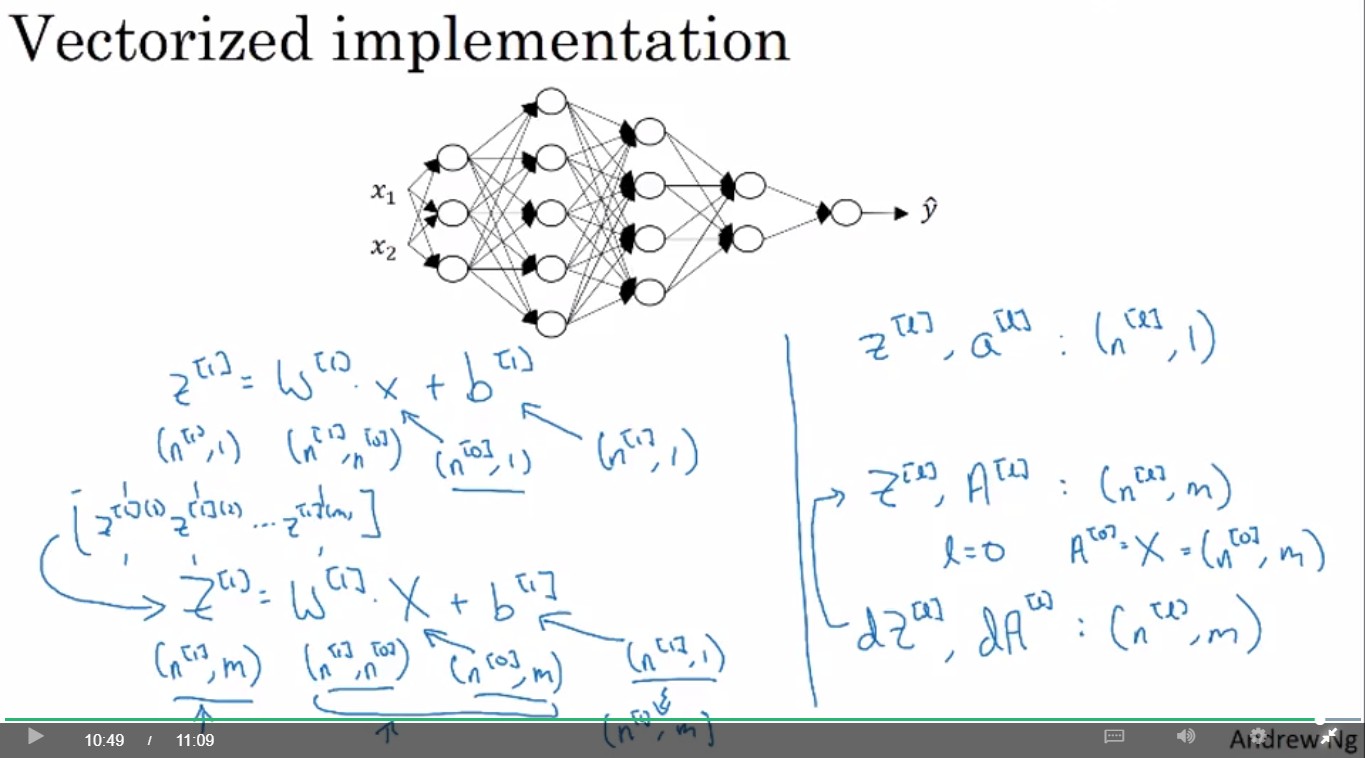 data有m筆,各矩陣維度
data有m筆,各矩陣維度
- : (,)
- : (, 1)
- : (, m)
- : (, m)
Why deep representations?
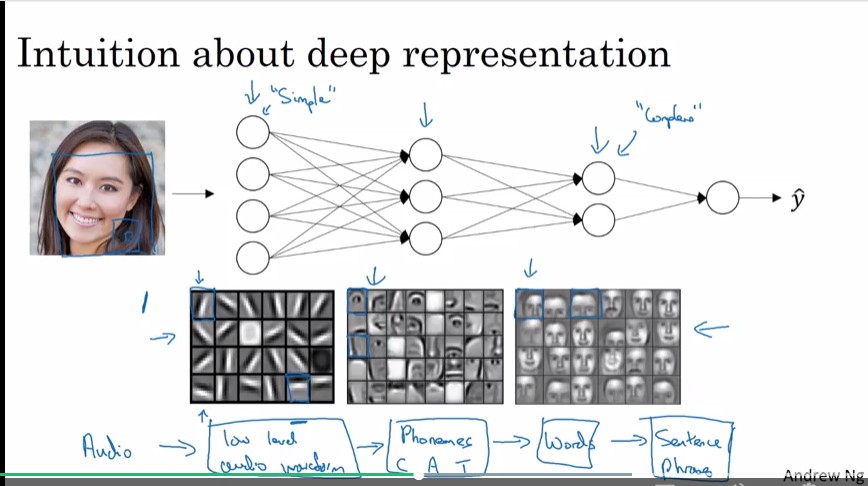 深度網路可以在hidden layer的第一層先學習到low-level的features, 後面的hidden layer再整合這些features, 從而實現複雜的功能, 像是臉部辨識、語音辨識...等。
深度網路可以在hidden layer的第一層先學習到low-level的features, 後面的hidden layer再整合這些features, 從而實現複雜的功能, 像是臉部辨識、語音辨識...等。
- 以臉部辨識為例, 第一層可能會從圖片偵測各種邊緣線條, 第二層利用邊界偵測眼、鼻、口之類特徵,第三層偵測臉的部分範圍。
- 以語音辨識為例, 第一層可能會從聲音偵測低階features(例如音調會提高或降低?),第二層利用這些低階features偵測phonemes(音素),第三層利用這些phonemes偵測單字。
同樣的function, 若可以由hidden units較少, 但較深的神經網路計算出來, 則較淺的神經網路需要較大量的hidden units來計算出這個function
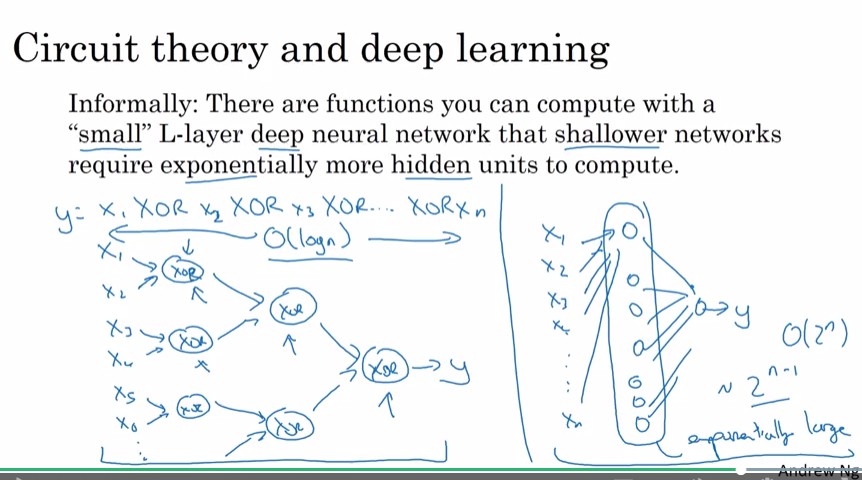 例如計算 時, 使用deep neural network 需要層, 第i層約需要個node。而若是使用單層hidden layer的neural network, 則需要約個node(為啥???)
例如計算 時, 使用deep neural network 需要層, 第i層約需要個node。而若是使用單層hidden layer的neural network, 則需要約個node(為啥???)
Circuit theory是啥
不像一般人總喜歡先套用Deep Neural Network, 在講者開始處理一個新問題的時候, 他總先使用Neuro-logistic regression(?), 然後試試看一層或兩層的hidden layer, 並以此作為parameter或hyper parameter, 如此才能找到最適合此問題的神經網路深度。 但是對於某些應用層面的問題來說, 很深(約幾十層hidden layer)的neural network會是最好的model, 所以deep learning才會看起來做得很好。
Building blocks of deep neural networks
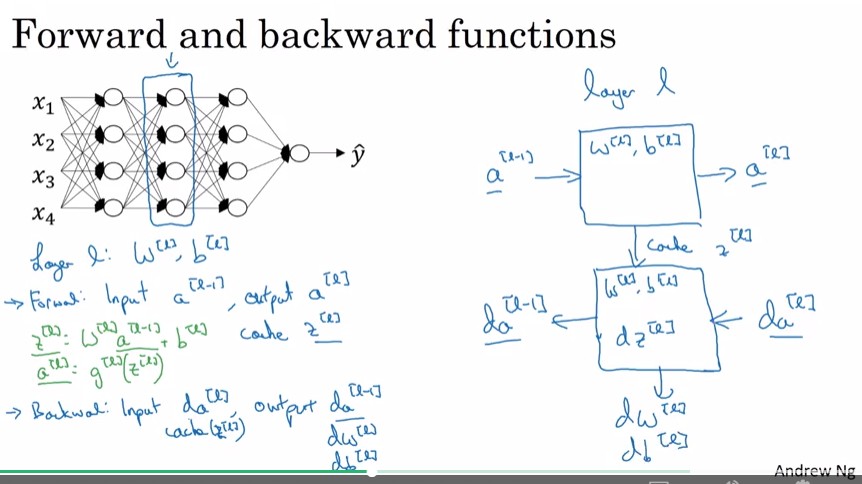 Forward propagation
Forward propagation
- 在計算 後也會將計算出的 暫存起來, 因為這可以用在之後的back propagation
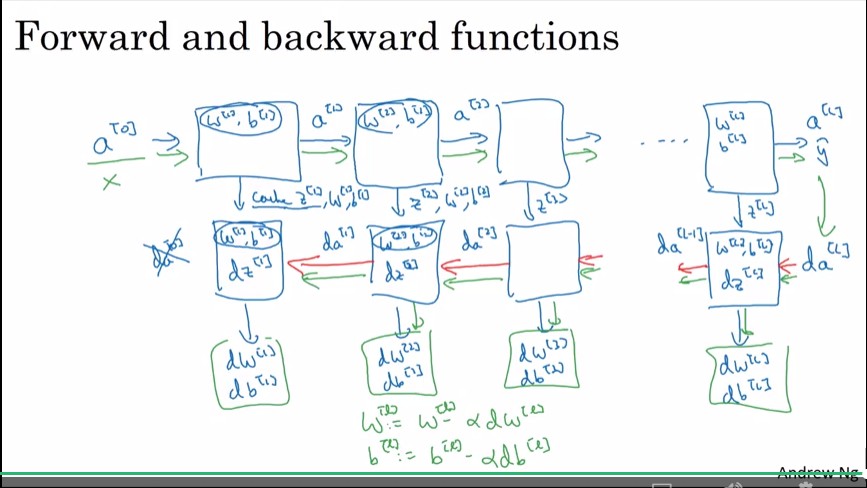
只可意會 不可言傳
Forward and Backward Propagation
這章好像是在說forward 跟 backward propagation要怎麼vectorize(吧?
 這不知道在說啥
這不知道在說啥
 左邊寫成Python(向量化之後)大約是右邊這樣
左邊寫成Python(向量化之後)大約是右邊這樣
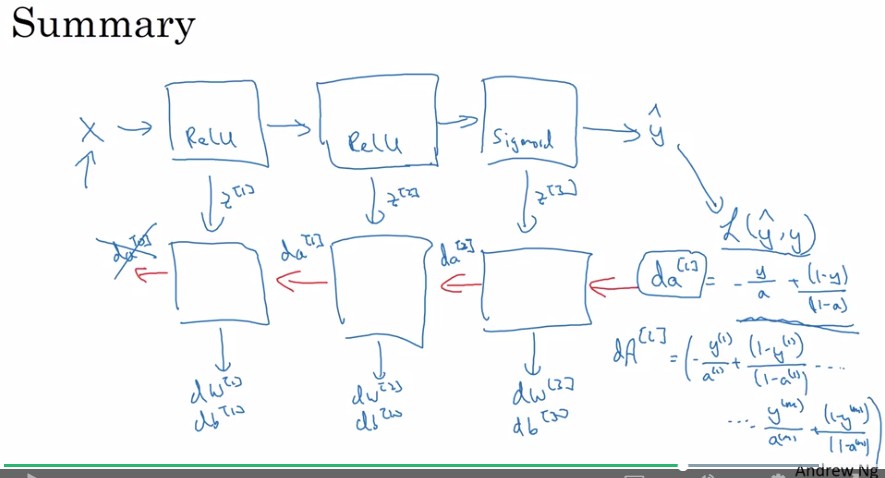 這結論o_o
這結論o_o
Parameters vs Hyperparameters
Parameters: 機器學習後得到的參數
Hyperparameters: 告訴機器如何"學習"的參數
- learning rate ()
- number of iterations
- number of hidden layers (L)
- number of hidden units ()
- choice of activation function
其他 Hyperparameters
- momentem
- mini batch size
- regularization parameters
結論
- Hyperparameters 會決定機器所學到的 Parameters
- 過往科學家的經驗不總是正確的, 多試試各range的hyperparameter(吧?
- hyperparameter tunning 在deep learning中仍然是一門有待改良的學問
What does this have to do with the brain?
這章大致在講Deep Learning和大腦的關聯性(其實沒什麼關聯嗎
Review:

哦哦哦哦 是簡體中文筆記!!!! 哦哦哦哦哦 連Code Assignment都在上面 哦哦哦哦哦哦哦