Object Localization
- classification & localization
- 分類並定位
- detection
- 圖片可能有多個物件
Classification with Localization
除了 output 類別,還要 output bounding box
本課程 notation
- 圖片左上角為 (0,0)
- 圖片右下角為 (1,1)
- bounding box
- b_x, b_y:bounding box 中心座標
- b_h, b_w:bounding box 高度 & 寬度
實際上的 output 向量:
- :有偵測到東西嗎? (background 以外的東西都算) 有的話要輸出下列的向量:
- :有東西的話要輸出 bounding box
- :那是什麼東西? (這邊假設東西只有一個)
label表示
圖片中如果沒有東西
- 其他 don't care,填問號
- 隨便 output 都可以的意思
Loss function
如果有東西 (即 )
如果沒東西 (即 )
上面是簡單說明,其實
- 可以用 logit loss
- 可以用 softmax loss
- 可以用 squared loss
但是上面這些 loss 的值域都不一樣欸,要怎麼 balance 這些 loss?
Landmark Detection
以 face landmark detection 為例: 若有 64 個特徵點,
output (129 = 1 + 64*2):
- : 有臉?
- 64個點的 x、y 座標
Object Detection
Sliding Window Detection
- 訓練一個 ConvNet,分類是否有該物件
- 用小的 sliding window 讓他去掃整張圖,用ConvNet分類
- 然後用更大的 sliding window 讓他去掃整張圖,將圖片縮放至 ConvNet 能吃的大小然後分類
- Computational Cost very high
- 因此比較適合簡單的 classifier,例如以往人們手工提取特徵然後套到線性分類器
- 不過這個缺點是能改善的,只要用 convolution 的方法實作 sliding window 即可,見下個影片
Convolutional Implementations of Sliding Window
先介紹如何將 fully connected layers 用 convolutional layers 實作
Turning FC layers into Convolutional layers
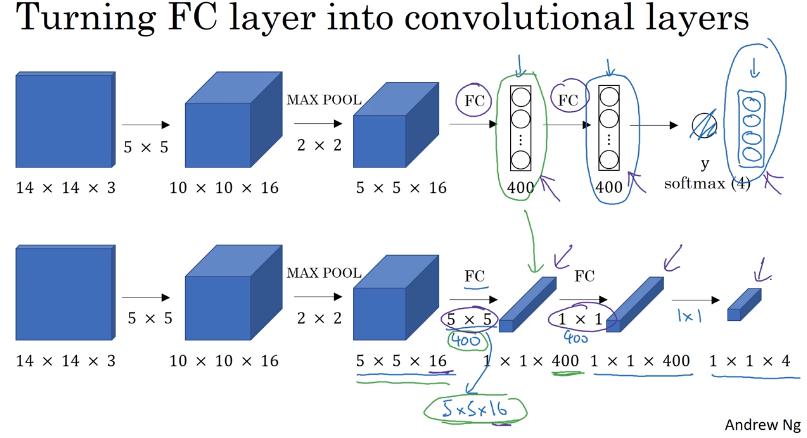
若希望 FC 的 output size 為 n 就使用 n 個 filter,filter size 和 input size 一模一樣
- channel 數本來就該一樣
- 長 & 寬要一樣
- 每個 filter 的 output size 就是 1
數學上,這種 implementation 和 FC 一模一樣
Convolution implementation of sliding windows
假設要掃 16x16x3 的 image,而訓練好的 ConvNet 就是上面提到的 input size = 14x14x3;output size = 1x1x4 的 4-class 分類器
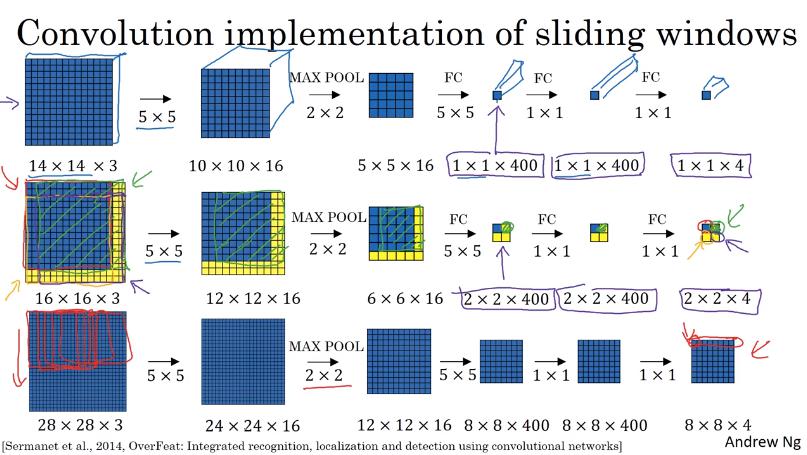
- 要 sliding window 之後輸入 ConvNet 太耗時了,而且許多運算都重複
- 直接拿 ConvNet 的第一層 filter 來掃整張圖片,後面的運算也都和 ConvNet 相同,只是每層的 output size 都不一樣了,最後的 output size = 2x2x4
- 2x2 的 output 分別對應到本來應該輸入到 ConvNet 的四個位置的圖片輸出
然而這種方式的 bounding box 位置不夠準,下個影片解決此問題
Bounding Box Prediction
YOLO 基本觀念
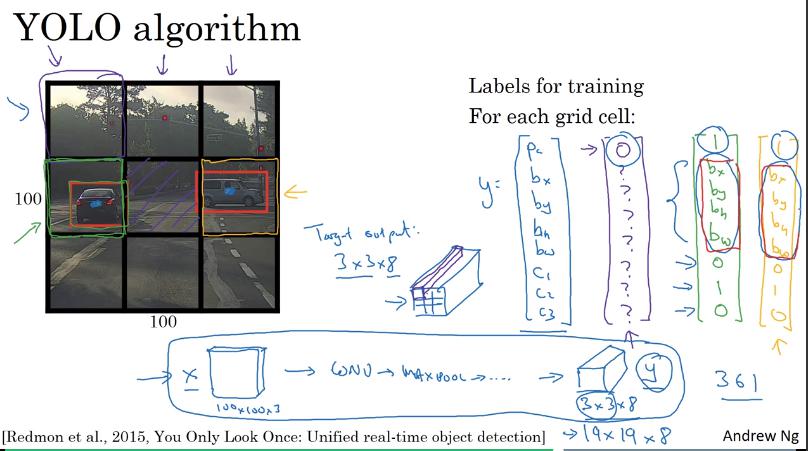
將圖片分成很多格子
- 此 example 為 3x3
然後應用之前的 Classification with Localization,對每個格子都做 training
- 只關注物件中心點是否出現在格子內
- output size = 3x3x8
- 3x3 是格子數
- 8 是 Classificatoin & Localization 的 output
- 實務上會讓格子比 3x3 密,例如 19x19,這樣可以避免多個物件在同個格子
- 結合了上面介紹的兩種方法
- Classification with Localization
- Convolution implementation of sliding windows,再跑格子的時候同樣不是一個一個輸入到 ConvNet,而是一次 conv 完成
- YOLO 很快,甚至可以即時
bounding box vectors
- 以格子的長寬為1,左上(0,0),右下(1,1) 為基準
下面介紹一些讓 YOLO 更強大的 trick
Intersection Over Union
Evaluating Object Localization

predicted bounding box 和 truth bounding box
- 計算交集
- 計算聯集
- 計算 交集/聯集 intersection over union (IoU)
慣例:'Correct' if IoU > 0.5
Non-max Suppression
可以確保演算法對同一個 object 只偵測一次

- 對於 19x19 每個格子都會有一個 output
- 同個 object 可能被不同格子都被偵測到
- 因此可能有多個 bounding box (以及機率)被輸出
- 先針對整張圖所有 bounding box 裡面 機率最高的 bounding box,高亮之後做
- 針對重疊率(IoU)高的那些bounding box,機率低的會被抑制/標暗
- 細節:機率為
- 之後再從整張圖的 bounding box(尚未被標記亮暗)中找出機率最大的,重複步驟 4.
- 標完全部之後,標亮的就是最終 prediction,搭拉~~
Algorithm

- 假設只有一種物件要偵測,就不會有
- 若有多種物件要偵測,則要對各物件各自獨立做 non-max suppression
Anchor Boxes
如果一個格子就想偵測多個 object 呢?
anchor box 同時也讓演算法能夠應付特殊情況 (極高or極胖的 object)
這邊沒很懂
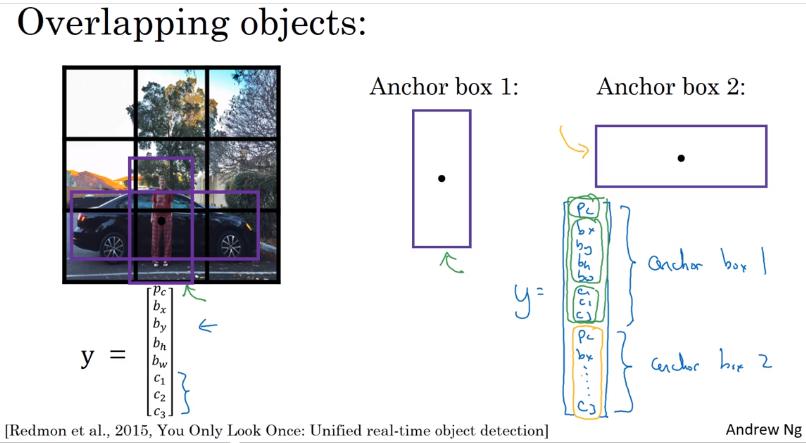
- 先定義好 n 個 anchor box (本例 n=2),shape 也長得不一樣
- y 的維度增加成 維
- 8 是本來的 output size
- 第 n 個 outputs 對應到第 n 類的 anchor box
- label 是分配給形狀像那類 bounding box 的向量
Algorithm

- 現在 output 從 3x3x8 變成 3x3x2x8
Example
(img)
- 沒法處理一個格子裡面的 object 數量大於 anchor box 數量
- 也沒法處理一個格子裡面的不同 object 形狀都同一個 anchor box 一樣
後來的 YOLO 改善
- 用 K-means 將兩種想找的 object 形狀結合起來,用來找 anchor (WTF
YOLO Algorithm
Training
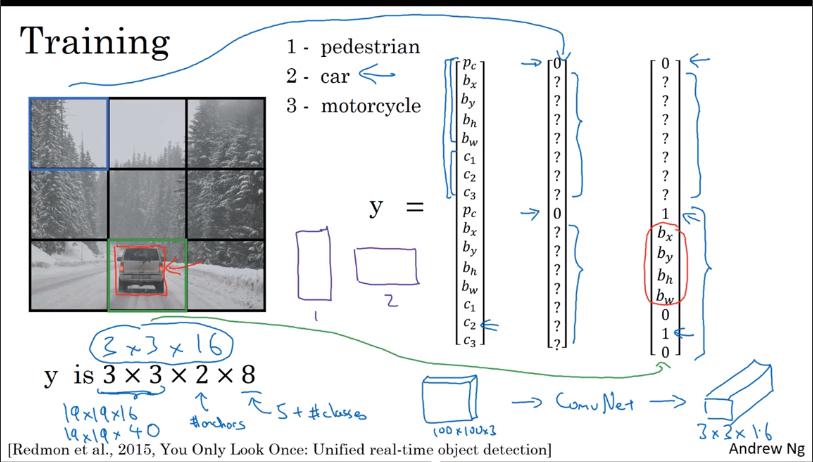
y 的 shape:
- 3x3: 格子
- 2: anchor box 數量
- 8: 以及類別數量
Predicting

- 先 output 所有 anchor box 的 bounding box
- 其他大概照舊
(Optional) Region Proposals
image 中某些地方顯然沒什麼有用的東西,但 NN 仍然會去掃
R-CNN (regions with CNNs)

- 先做 segmentation,然後發現一些區塊可能是有東西的
- 再丟到 ConvNet
Faster Algorithms

- R-CNN 很慢
- 註:R-CNN 不全然信任我們給的 bounding box,它自己也會給出一個 bounding box (???啥),所以 bounding box 滿準的
- Fast R-CNN 應用了前面提到的 Convolution implementations of Sliding window
- 但是 propose region 部分的速度還是很慢
- Faster R-CNN
- 使用 Convolutional network 來 propose region (之前是使用傳統的 segmentation algorithm 來 propose)