Notation
- 表示第i筆 training data 的sequence中,第 t 個element
- 表示 x sequence的長度
- 第i筆training data 的 x sequence長度
- 表示 y sequence長度
x: Harry Potter and Hermione Granger invented a new spell.
- : one hot encoding in my dictionary with a huge amount of word.
- if not in dictionary, then use a fake word that represents "UNK", means unknown.
Recurrent Neural Network Model
Recurrent Neural Networks

Simplified RNN notation
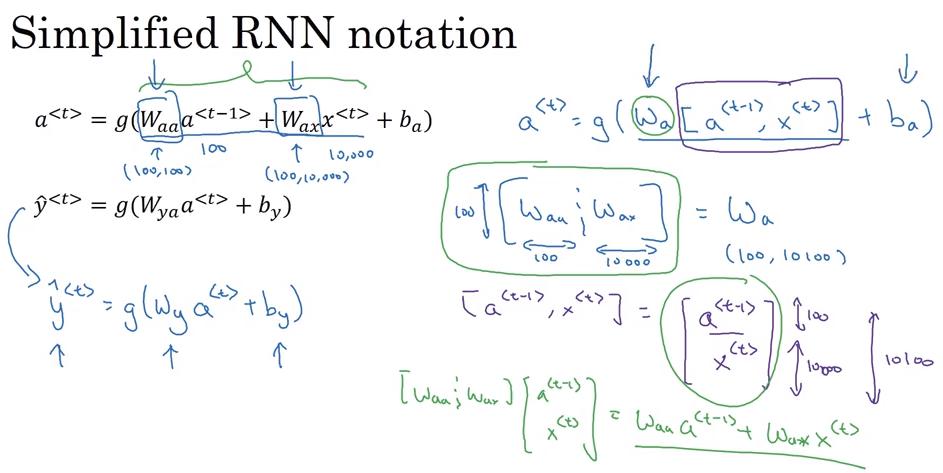
,g(x)通常是tanh或ReLu
- 可以表示為
- 因此若 a的shape是(100,1), 的 shape 為 (10000,1),則 shape of
- : (100,100)
- : (100,10000)
- : (100,10100)
,g(x)通常是 sigmoid
- 可以表示為 沒什麼差別,估計為了之後表示方便才這麼寫
和 可以簡化成
- 此時
- 因 , = 原式
額 我發現這篇中文筆記 寫的好多了, 索性不寫ㄌ
補充中文筆記2
還是補充一下好了
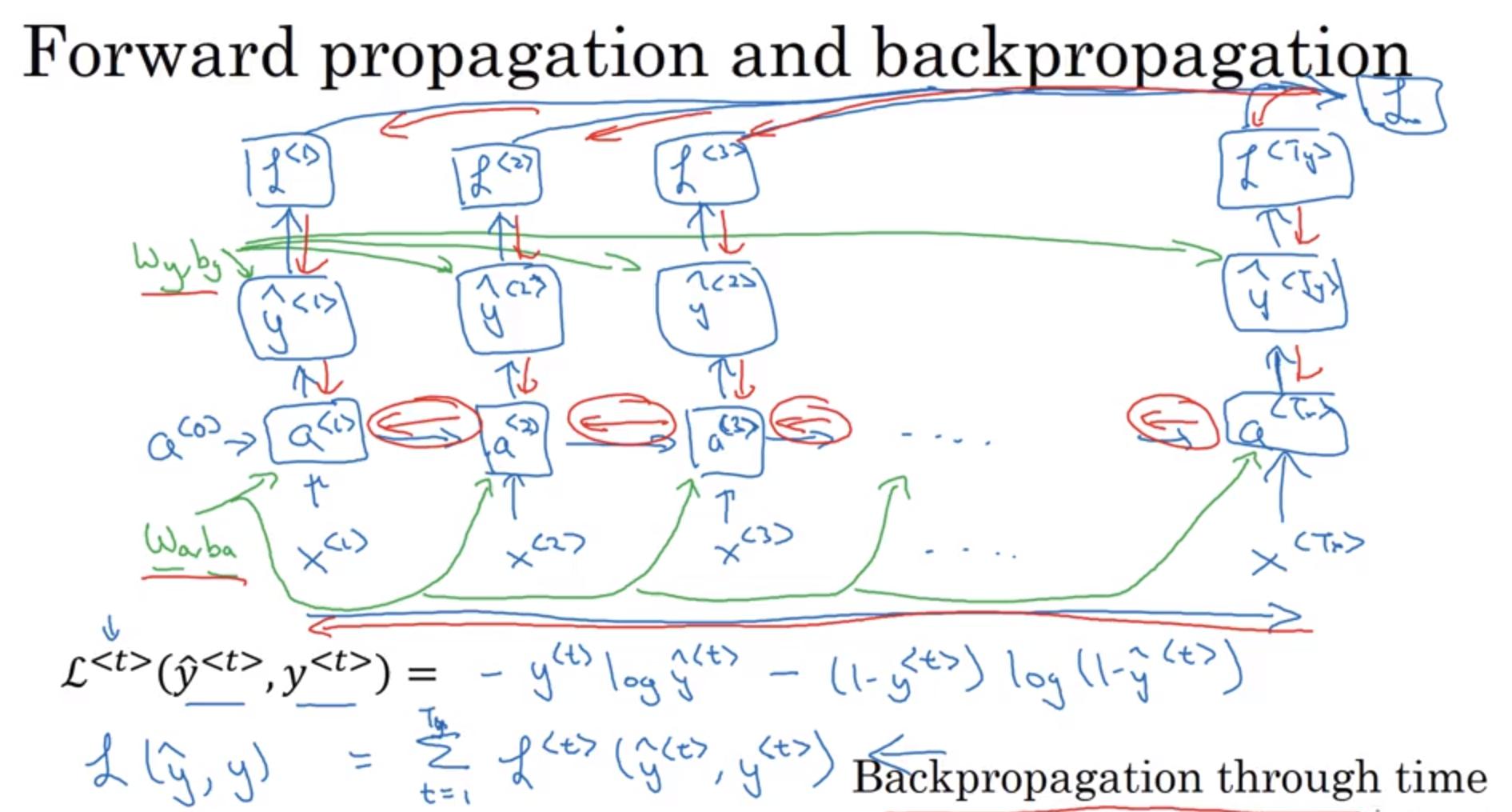
Backpropagation through time
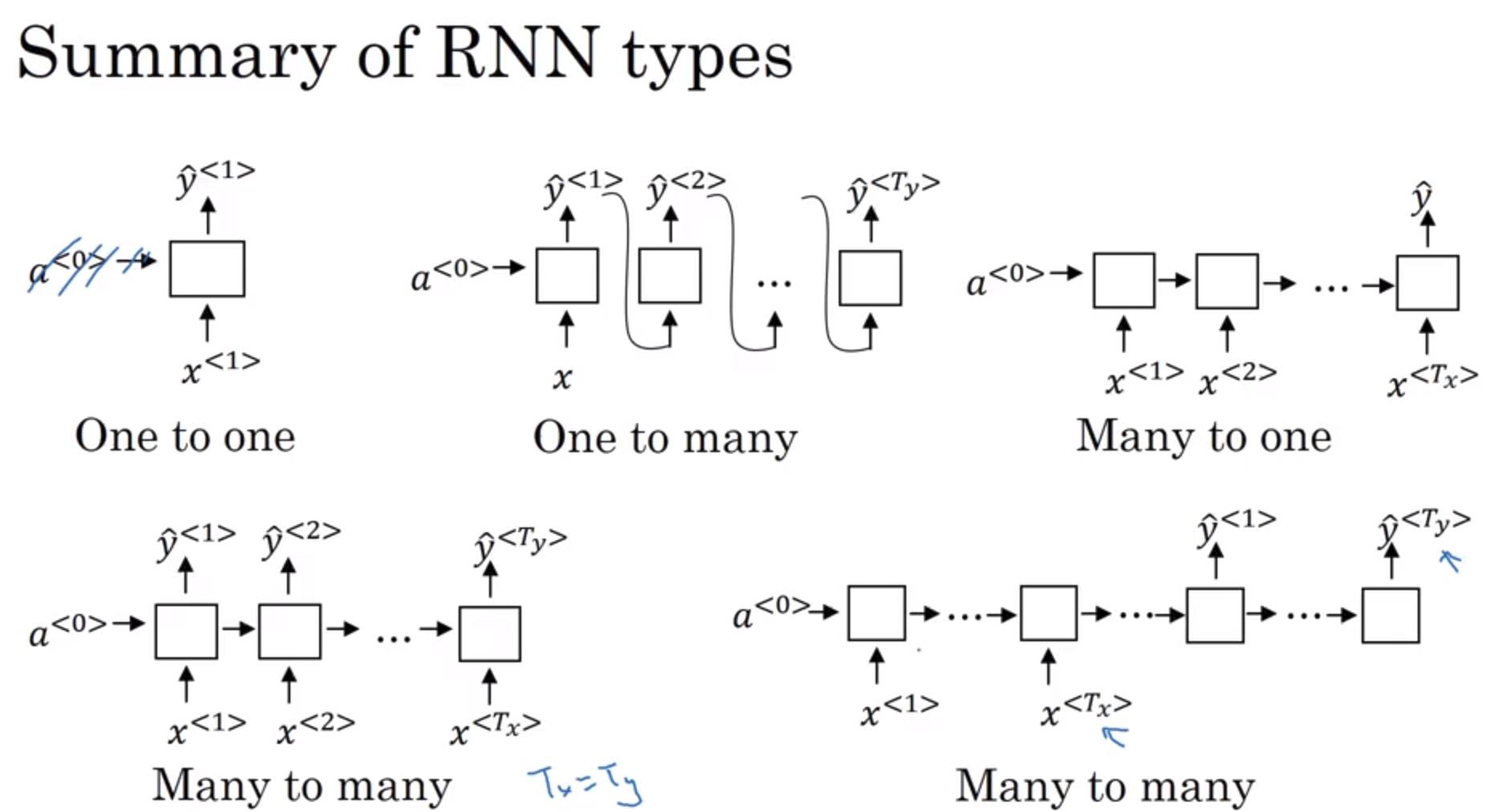
Different types of RNNs
types of RNNs and examples
- One to many: sequence generation / music generation
- Many to one: sequence classification / sentiment classification
- Many to many (with the same size): name-entity recognition
- Many to many (with different size): machine translation
Language model and sequence generation
RNN model (sequence generation)
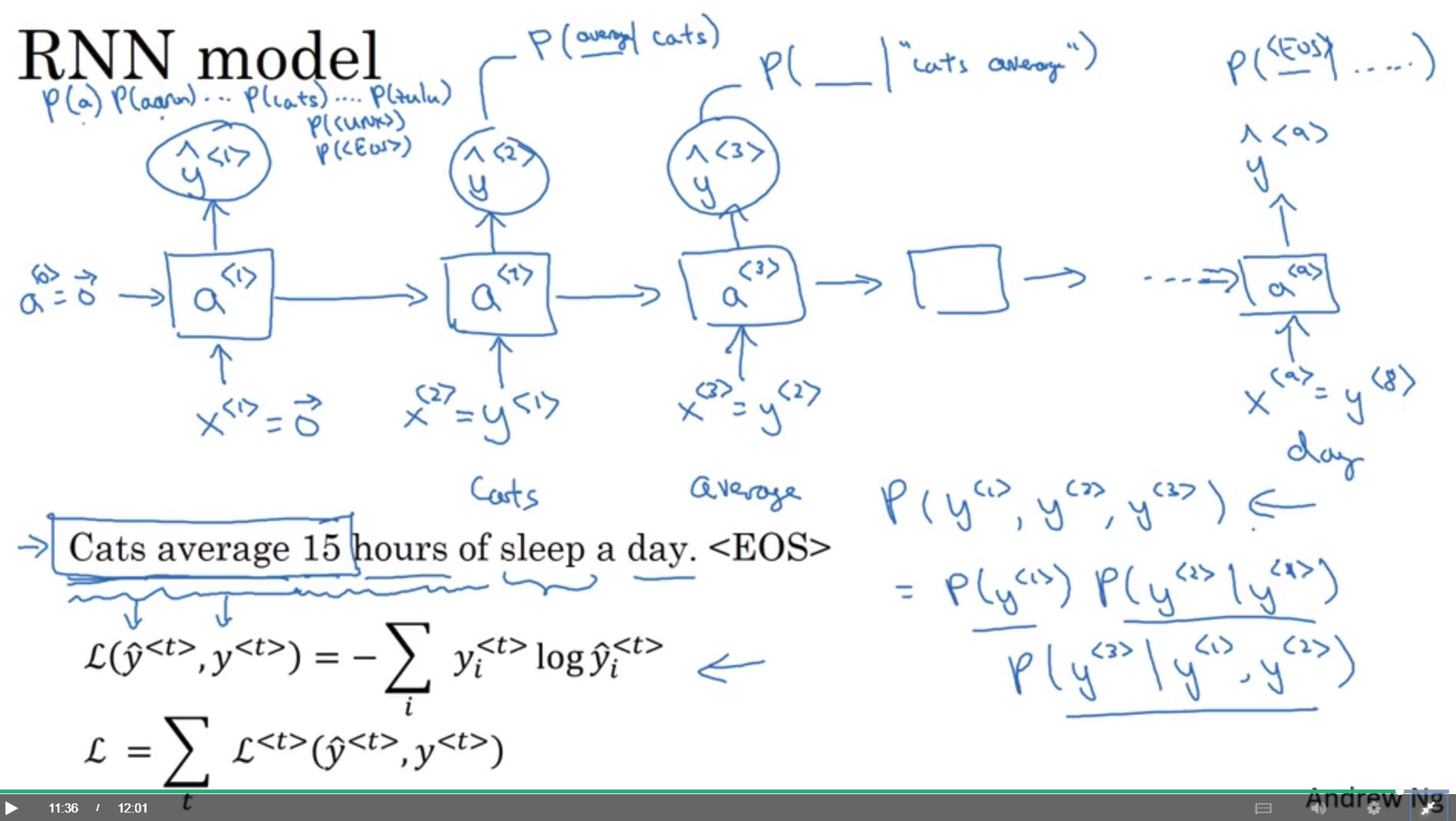
- 前一刻的y (即 ) 會被當成這個時刻的 input (即 )
這樣的 model 可以做到
- 給定前段字詞 sequence,預測後面字詞出現的機率
- 直接預測某組字詞 sequence 出現的機率
- 利用條件機率即可,
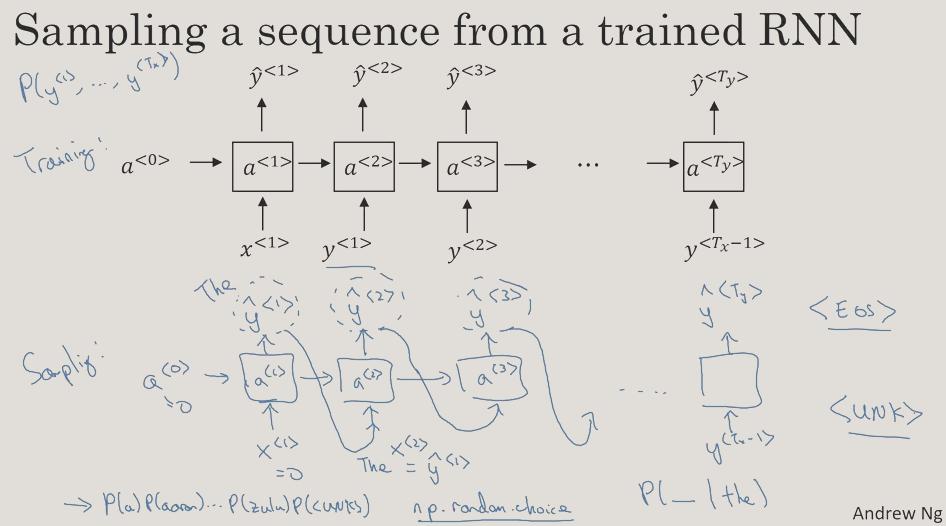
Sampling novel sequences
上一節 訓練完一個Sequence generation的 RNN,我們要怎麼從 model 中採樣出一個 sequence 呢
Vanishing gradients with RNNs
RNN 可能有 梯度消失 & 梯度爆炸 的問題
梯度爆炸很容易可以發現,因為參數可能變 NaN,原因為 numerical overflow
- 可以用 gradient clipping 解決
梯度消失較難解決,接下來會介紹 GRU,有效對付gradient vanishing問題,能將資訊記的更為長久。
Gated Recurrent Unit (GRU)
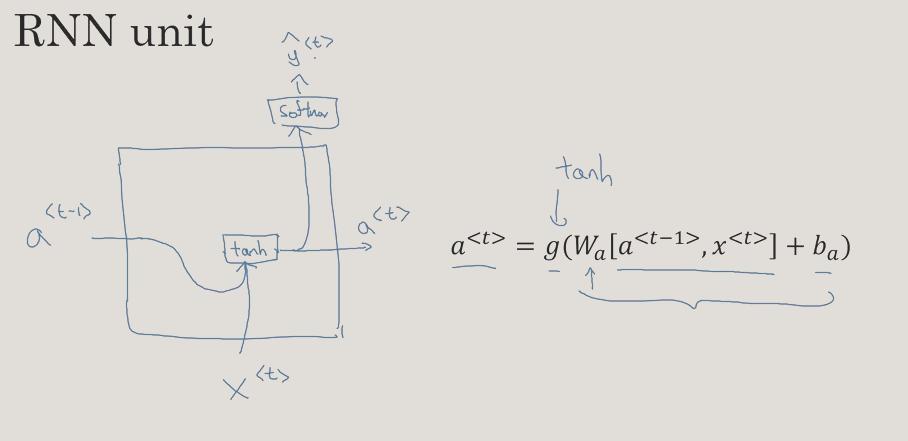
RNN unit
GRU (simplified)
 Notation: why use these symbol or alphabet
Notation: why use these symbol or alphabet
:
- (Gamma) for Gate
- for memory cell, 目前在 GRU,,然而到了 LSTM 這兩個值會不一樣,因此現在先分開寫
- for update, when to update c
- for relevant, 前一個 和 的相關性
: 值為0則記住之前的,1則忘記之前的,更新新的記憶
Formula
-
- 是要用來取代 的候選 (?)
GRU 最重要的概念
- 同時也是圖中左方紫色區塊的運算內容
- 可以防止 gradient vanishing,因為即使 很小,小到接近0,那麼 就會幾乎將 保存起來,也間接防止了梯度消失(?)。
- 注意 * 是 element-wise 的運算子。
- 也是一個 vector,因此他其實代表了 這個 vector 中,哪些元素需要被更新,哪些不用。
Full GRU

- : 不懂為啥要加這項,不是可以讓 自動學出來嗎?
- 它代表的是 和 之間的關係,應該類似上方提到的 也是 element-wise 的關係
Long Short-Term Memory
與 GRU 不同的地方是:
- 不再與 相等,而是 與 的 element-wise 乘積
- 決定 的 gate 不再只有 一個,而是 和 共同決定
- update gate 應該有個別稱叫 input gate (吧
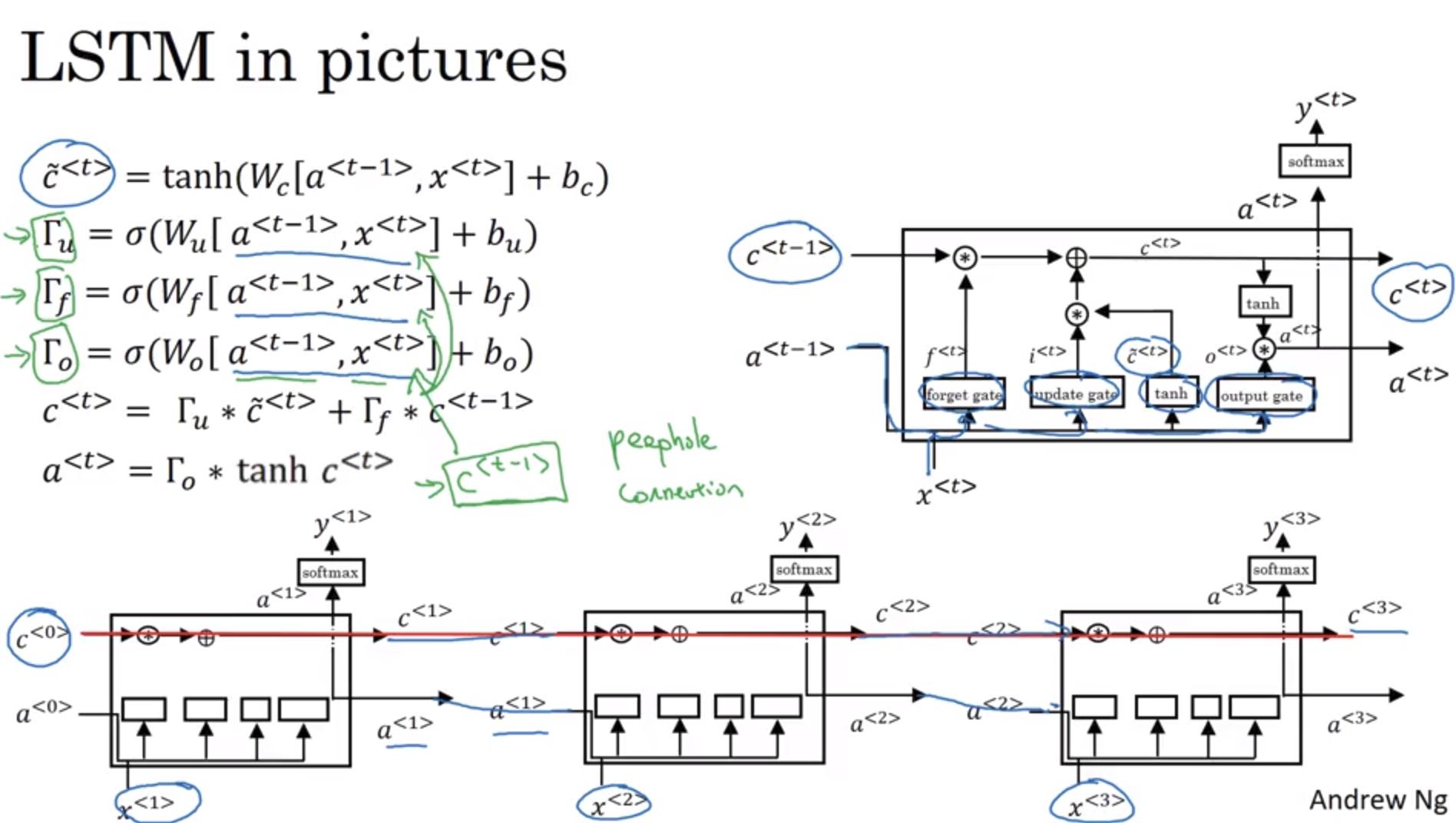 若 不只受 和 影響,還受到 影響,則我們稱為 peep hole connection
若 不只受 和 影響,還受到 影響,則我們稱為 peep hole connection
- 有個技術細節:{% math %}c{% endmath %} 是一個 vector,而 c 的第 n 個 element 只會去影響 {% math %}\Gamma{% endmath %} 的第 n 個 element
LSTM & GRU 比較
- GRU 相對簡單,更容易建構出較大的網路
- GRU 計算速度較快
- LSTM 更強大而有效 (好籠統@@)
- 要在 GRU 或 LSTM 中選一個,建議先用用看 LSTM
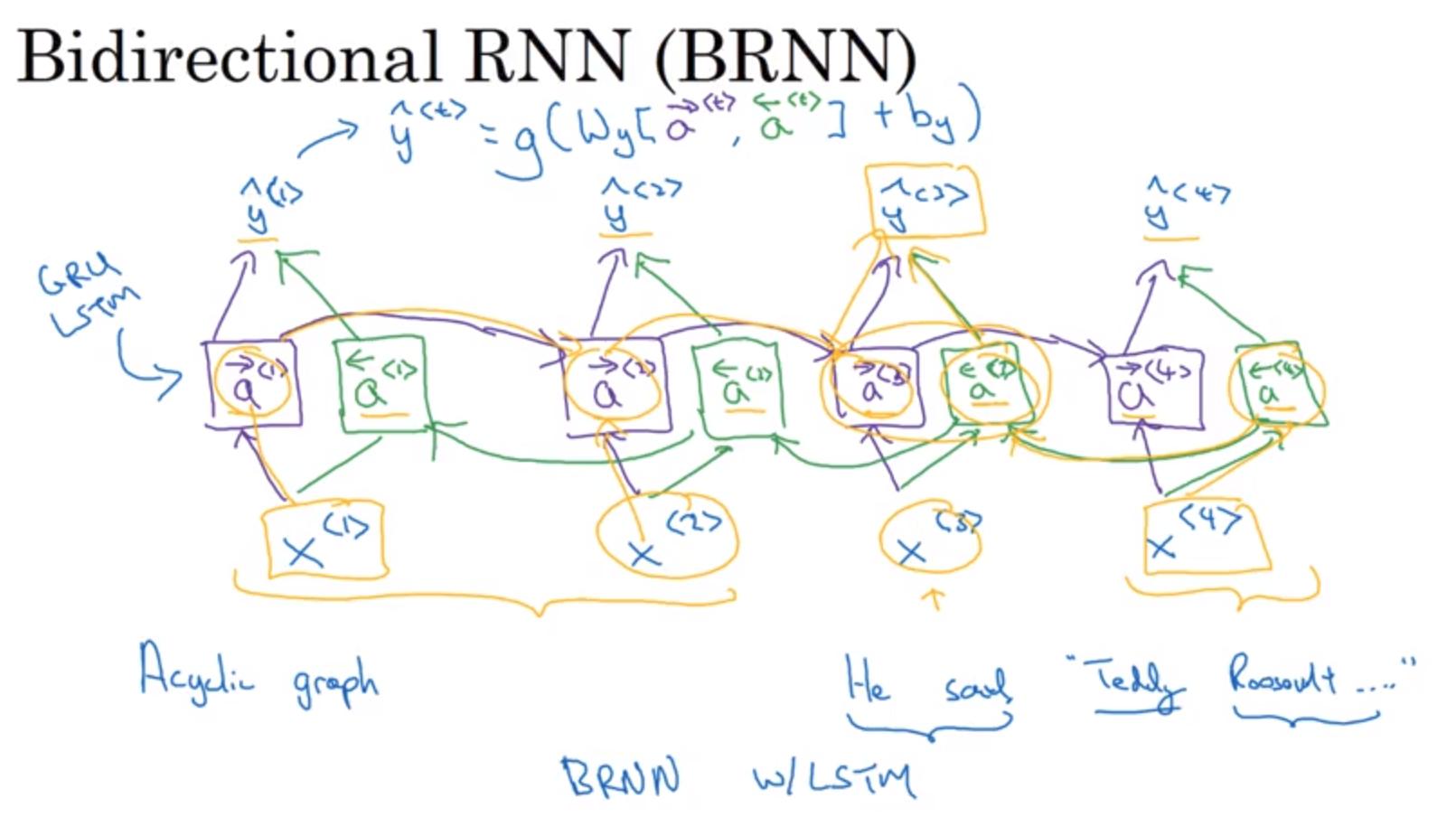
Bidirectional RNN (BRNN)
Deep RNNs
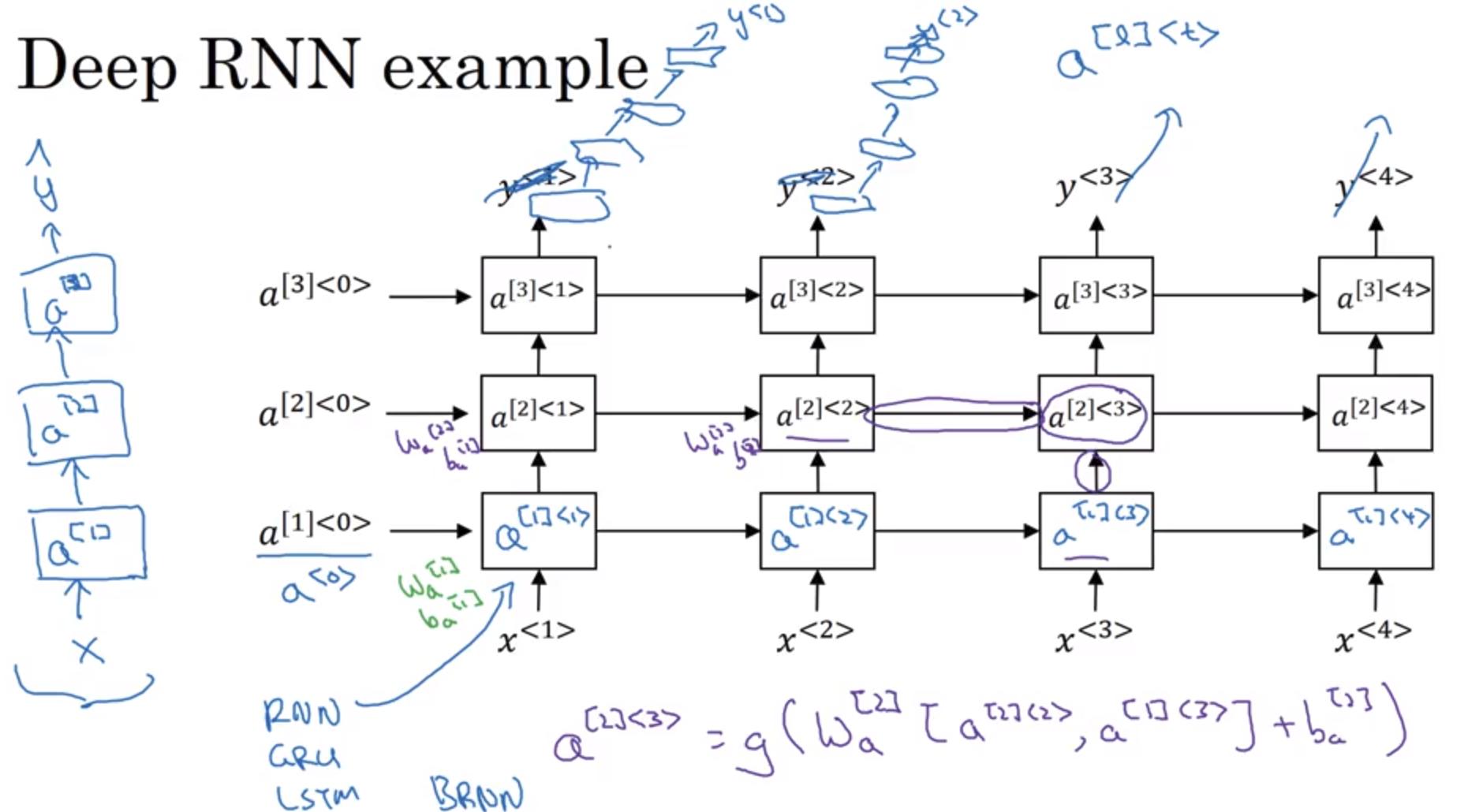
- 左方是簡化版的 deep RNN,右方較詳細
- : 第 層的第 個element
- 3層的recurrent layer 就夠多了,因為時間軸上的層數是非常多的(雖然我們無法直接看出來