Why look at case studies?
Classic Networks
LeNet-5
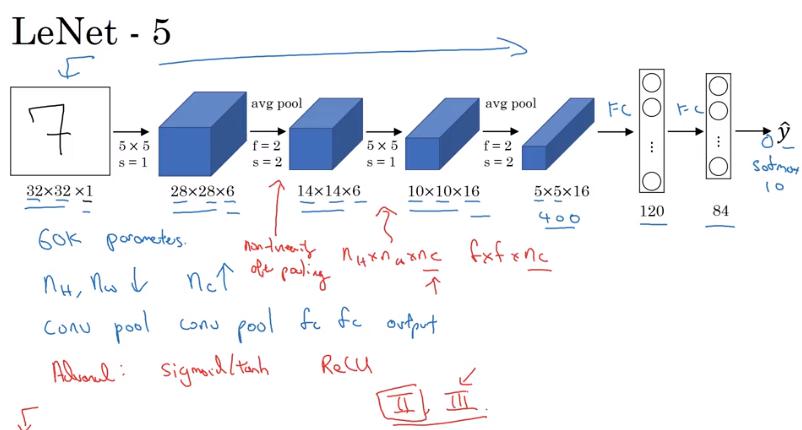
- 約 6萬個參數
- 論文不好讀
AlexNet
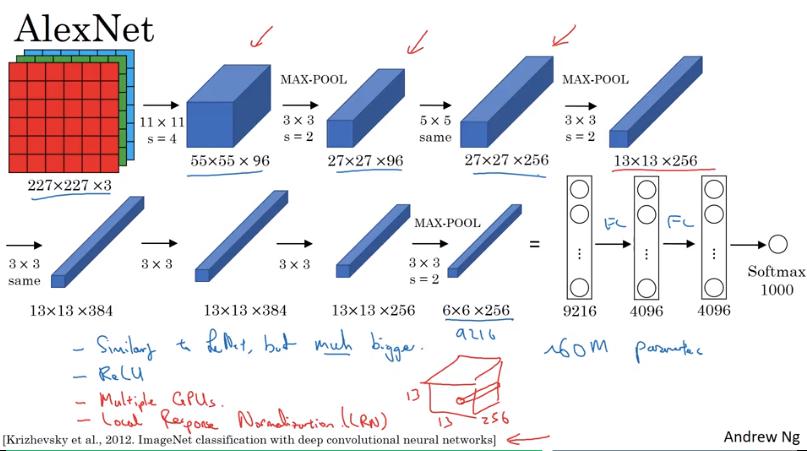
- 第一層 convolution stride = 4,第二層 convolution stride = 2
- 和 LeNet 很像,但有約 6千萬個參數
- ReLU
- Local Response Normalization
- 對每個 pixel 的 所有 channel 做 normalization
- 後來的研究發現沒啥用
- 論文和其他比起來較容易閱讀
VGG (VGG-16)
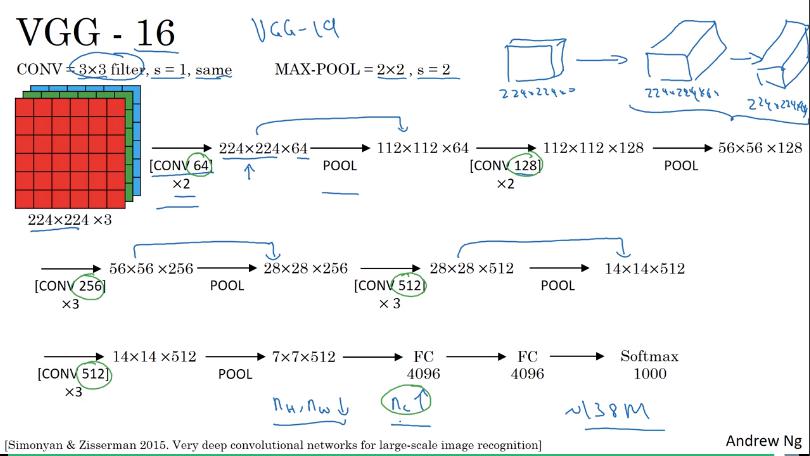
- 所有 convolutional layer 設定都相同
- filter size = 3x3
- stride = 1
- padding = 'same' convolution
- 所有 pooling layer 設定也都相同
- max pooling
- filter size = 2x2
- stride = 2
Network 架構
- conv64 * 2層
- pool
- conv128 * 2層
- pool
- conv256 * 3層
- pool
- conv512 * 3層
- pool
- conv512 * 3層
- pool
- fc4096 * 2層
- softmax1000
- VGG-16 指的就是16層有權重
缺點:
- 參數非常多,約 138 million,即13億8千萬
VGG-19
- 更大的 network
- VGG-16 幾乎和 VGG-19 一樣好,因此許多人都用 VGG-16
- 系統化的降低 output 的 w和h,增加 channel
ResNets
Residual Block
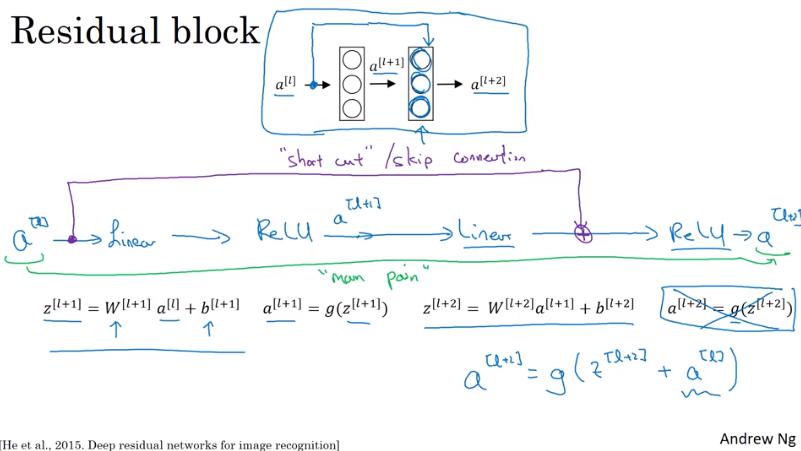
自己畫

- 傳遞 output 到隔 1.5 層 (傳到隔兩層的 ReLU 之前)
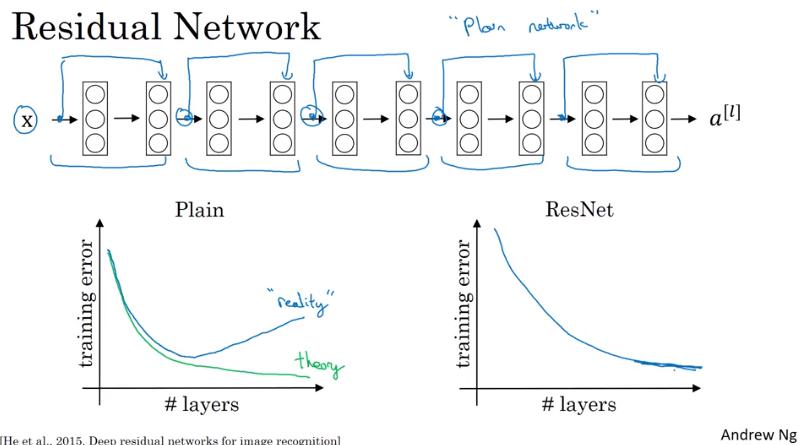
- 理論上,深度越深的 NN,training error 應該要越低,實則不然
- 因為到達一定深度之後實務上開始變得非常難 train,像之前提到的 gradient vanishing/exploding 的問題
Why ResNets Work
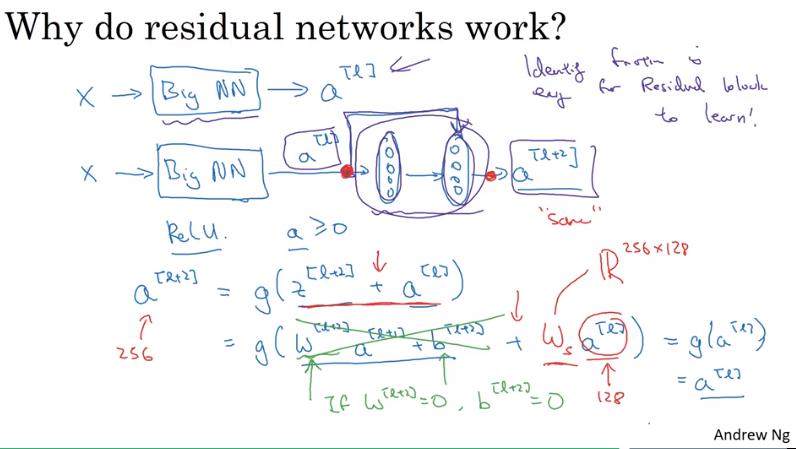
- 當 W 和 b 都為 0 時,這兩層的 output 結果就變成 identity function,亦即加了這兩層 layer 完全不會傷害到 NN 的性能
- 最差的情況下只是毫無作用,output = input
- 註:若使用 L2 regularization (weight decay),則 會變小
- 在 ResNet 中,常會使用 same convolution 來保證 和 的維度相同,如此才能相加。
- 就算 和 的維度不同,也可以在 前面乘上 使得維度相同, 可以是 learn 出來的,也可以是單純將 做 zero-padding。
Networks in Networks and 1x1 Convolutions
![]()
- 1x1 的 filters 可以想像成一個 fully connected network,連接到某個 input pixel 的所有 channel 上,output 就是 filter 的數量
- 乾我就一直超納悶為啥 1x1 的 convolution 要叫 network in network,終於明白ㄌ 太神拉
![]()
- 若想縮小 output 的寬&高,可以使用 pooling layer
- 但是想縮小厚度呢? 就可以用 1x1 的 convolution。使用幾個 filter,output 就有幾個 channel
- 當然想要厚度維持一樣或增加也是可以,使用和 input channel 同等數量的 filter 即可,此時 1x1 convolution 所做的就是增加 output 的複雜度 (non-linearity),如此一來,NN 的能力更強、學習更複雜的函數。
Inception Network Motivation
還在猶豫要用 3x3、5x5、7x7 還是pooling layer嗎? 怎麼不全部摻在一起做就好了呢ㄏㄏ
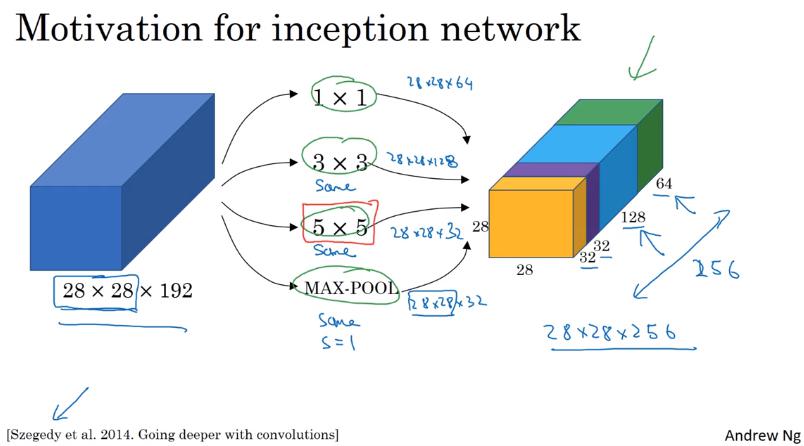
- 對同一個 input image 做各種 convolution 時,padding 使用 same convolution,這樣 output 的 width 和 height 可以保持一樣,如此就能以不同 channel 的形式合併。
- pooling 也和 convolution 同理,這時候為了使 output size 相同,也要做 padding (same convolution),因此跟以往的 pooling 不太相同。
- pooling 的 stride 似乎也要設 1,下則影片有提到
- 這時候,就可以讓 NN 自己決定要採用什麼樣的 convolution 以及 pooling 較恰當。
The problem of computational cost
![]()
- 只計算 5x5 的 convolution,就要做約 1億2千萬次的乘法運算
- input: 28x28x192
- output: 28x28x32
- 使用 1x1 的 convolution 作為 bottleneck layer 可以減少運算量至 十分之一,約 1千200萬次的運算,而且不太傷害 performance
- input: 28x28x192 (同上)
- 1x1 conv (bottleneck layer) output: 28x28x16
- output: 28x28x32 (同上)
Inception Network
Inception module
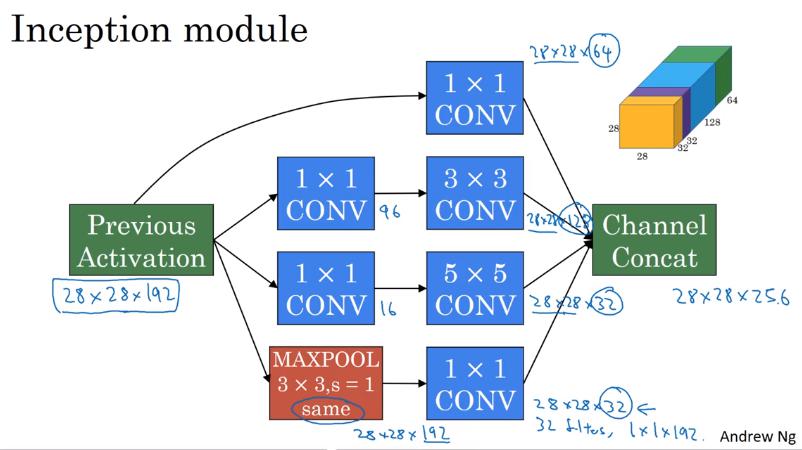
- 此時 pooling layer 的 output size 會跟 input size 一樣都是 28x28x192,channel 過多,因此使用 1x1 conv 縮小 channel 數
- 此 example 使用 32 個 filter,因此 output channel = 32
- 最後把所有 output 以不同 channel 結合起來,這樣就是一個 Inception module
Inception network
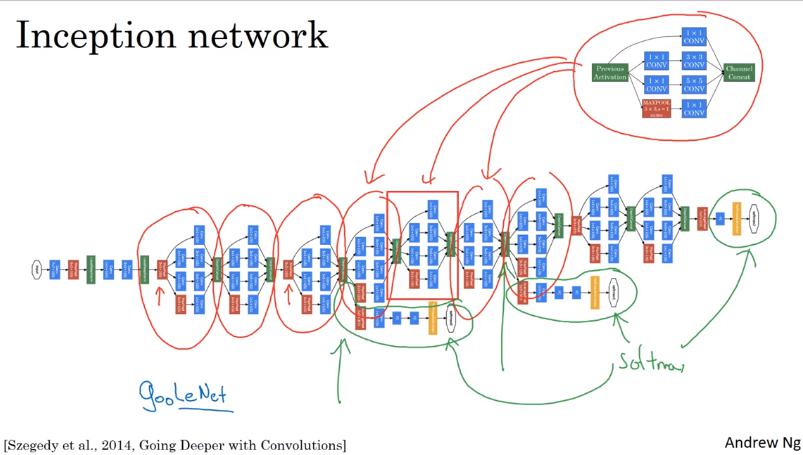
- 把一堆 Inception module 跟 pooling layer 合併起來就變 Inception Network
- 有個細節是,除了最後一層接 softmax,Inception 還會把一些 hidden layer 也外接 softmax 來預測 label。
- 這是為了確保 Inception 中間層的特徵也有一定的意義,可以視為 regularizing effect,避免 NN overfitting (why?)
- 又稱 GoogLeNet (Google 員工開發的,向 LeNet 致敬)
Inception 名稱的由來

WTF 我就一直納悶怎麼跟全面啟動的英文名字一樣,居然真的是XDDDD
- "We need to go DEEPER. "
- we need to use DEEPER network.
論文裡面直接 cite 這個 meme ( ͡° ͜ʖ ͡°)
