Python and Vectorization
Vectorization
寫Python code時盡量以向量運算取代 for迴圈,
將提升百倍效率。
More Vectorization examples
以Logistic Regression為例 Vectorize:
原Algorithm
如上圖, 在feature只有兩個的時候只有dw1, dw2兩個變數, 可以直接指定0, 然而在feature有一千個的時候就必須寫for-loop執行1000次來指定dw[]陣列內容為0, 非常沒有效率, 所以利用numpy的built-in function來提高效率
dw = np.zeros((nx,1)) # nx為feature數量
同理, 、...等可以簡化為
dw += x_i * dz_i # x_i為第i筆資料的向量形式
, ...簡化
dw /= m # 向量中的所有元素都除m
Vectorizing Logistic Regression

各矩陣
- : 大小為 1 * nx (w 大小為 nx * 1)
- X: 大小為 nx * m (m筆data, 每筆data有nx個feature)
- b: 大小為 1 * m , 內容皆為b
- Z: 大小為 1 * m, 內容為 x + b, Python向量化:
Z = np.dot(w_T,x) + b - A:
Vectorizing Logistic Regression's Gradient Output

Broadcasting in Python

上圖為各食品每100克所含營養成分的卡路里, 若想計算各食品的Carb, Protein, Fat 卡路里的所佔%數, 要如何不透過 for-loop 計算?
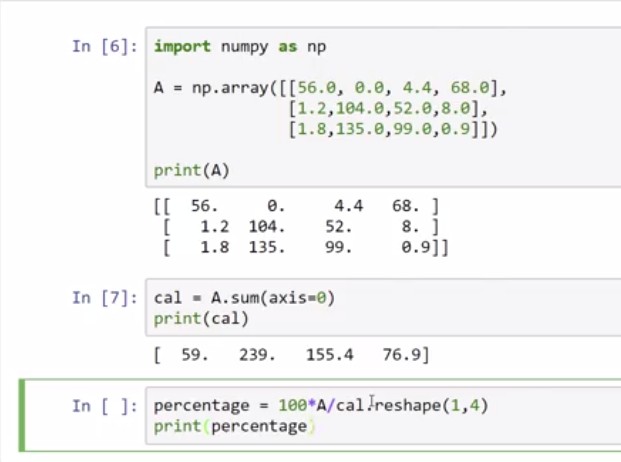
咩幾可
附註:
A.sum(axis=0) # 在計算總和的時候是以直行計算, 若要橫列計算則axis = 1
cal.reshape(1,4) # 雖然這裡的cal維度本來就是1*4了, 但在coding時若不確定matrix本來的維度, 還是reshape過較保險, 而且reshape並不耗效能, 所以想call就call別害羞 >///<

A note on python/numpy vectors
a = np.random.randn(5)
print(a.shape) # a會是rank-1的陣列(5, ), 不是row vector也不是column vector
a = np.random.randn(5,1)
print(a.shape) # a會是維度為(5,1)的column vector矩陣
a = np.random.randn(1,5) # 同理, 維度(1,5)的row vector矩陣
如果不是很確定程式中的a維度到底是不是(5,1)
assert(a.shape == (5,1)) # 若a的維度不是(5,1)則會AssertionError
assert a.shape == (5,1) , "a is not a 5*1 matrix !!!"
# 在使用直譯器時, 若下 -O 指令, 則直譯器會將__debug__設為False, 不會執行assert語句
# assert也可以用做程式的document
盡量不要在程式中使用rank-1的陣列