ML Lecture 19: Transfer Learning
用在哪?
- 相同domain,不同task,例如input都是動物的圖片,但是ㄧ個task要做貓狗分類,另一個要做獅子老虎的分類。
- 不同domain,相同task,例如task都是分辨貓狗,但是一個input是相片,ㄧ個input是卡通圖片

Labeled Source Data + Labeled Target Data
- Fine Tuning
- Multitask Learning
Fine Tuning
先使用大量 source data 做訓練來initialize權重,再使用少量target data 訓練(fine tune)以微調,但是因為target data數量通常很少,容易導致overfitting
- 我們care的是在target domain上做得好不好
- 若 target data 非常少,只有幾個example,則稱為 one-shot learning
Conservative Training
![]()
- 可以看做是一種regularization
- 方法其一:控制output讓target data訓練前後output不要差太多
- 其二:控制parameter在target data訓練前後不要差太多,例如新model和舊model參數的l2-norm越小越好
Layer Transfer
- 影片15:10秒開始有誤,把 target data 講成 source data
- Speech: 通常copy 最後幾層,重新訓練input的那幾層
- 從"發音方式" 轉換到 "預測結果" 與說話者較無關係
- 從"聲音訊號" 轉換到 "發音方式" 會因人而異
- Image: 通常copy前面幾層,重新訓練靠近output的那幾層
- 若target data夠多了,則可以copy完layer之後,再fine-tune整個model
Multitask Learning
- 我們同時關注target domain和source domain做得好不好
- deep learning based 的方法很適合

- 當 input feature 相同,可以share的時候,前幾個layer可以共享,後幾個layer分開
- 但是若連 input feature 都不同,就先用一些layer投射到同個domain上,中間幾層共享,後面幾個layer再分開(覺得中間幾層有共通性,可以共享時才使用)
Progressive Neural Network
 transfer learning能不能work取決於兩個task到底像不像,但我們不知道怎樣才像,於是只能trial&error,
但 Progressive Neural Network 可以在兩個不怎麼像的task上work
transfer learning能不能work取決於兩個task到底像不像,但我們不知道怎樣才像,於是只能trial&error,
但 Progressive Neural Network 可以在兩個不怎麼像的task上work
- 訓練完task1的model之後,將task1_model的參數固定住,開始訓練task2的model
- task2 的 NN 每一個 hidden layer 都會去接 task1的 hidden layer output
好處:
- task2的data不會動到task1的model,因此task1的performance不會比原來更差
- task2的model可以把task1的hidden layer output 權重設為0(應該是訓練出來的?),因此就算接了task1的model之後performance再怎麼差,也不會跟單獨訓練task2的model差太多
Labeled Source Data + Unlabeled Target Data (Domain Adaptation)
- Source data: ,一般視為training data
- Target data: ,一般視為testing data
Domain-adversarial training

- feature extractor 希望可以消除不同domain的feature的domain特性
- domain classifier 希望可以分辨不同domain之間的feature差異
- label predictor 希望可以透過feature預測label
- feature extractor output要同時騙過 domain classifier 並且使得 label predictor 做得好
- gradient reversal layer
- 因為 feature extractor 的目的和 domain classifier 相反,因此在domain classifier傳遞gradient給feature extractor時,要將gradient變成反方向
有點問題不太懂
- 現在feature extractor希望在不同domain做到minimize label predictor的loss,同時maximize domain classifier的loss,但是另一個domain是unlabeled data,所以label predictor沒有拿target的domain data來train,那要怎麼保證在 target domain 的資料能夠預測出正確的 label? Domain-Adversarial Training of Neural Networks, JMLR, 2016 Unsupervised Domain Adaptation by Backpropagation, ICML, 2015
Zero-shot learning
- Source data: ,一般視為training data
- Target data: ,一般視為testing data
和 domain adaptation 很像,source data 有 label;target data 沒 label。但是這時 Source data 和 Target data 是不同的 task,例如Source data辨認貓狗,Target data 辨認草泥馬
 從辨認 class 改成辨認 attribute,然後testing時,再看attribute最接近誰
從辨認 class 改成辨認 attribute,然後testing時,再看attribute最接近誰
Image domain 的做法
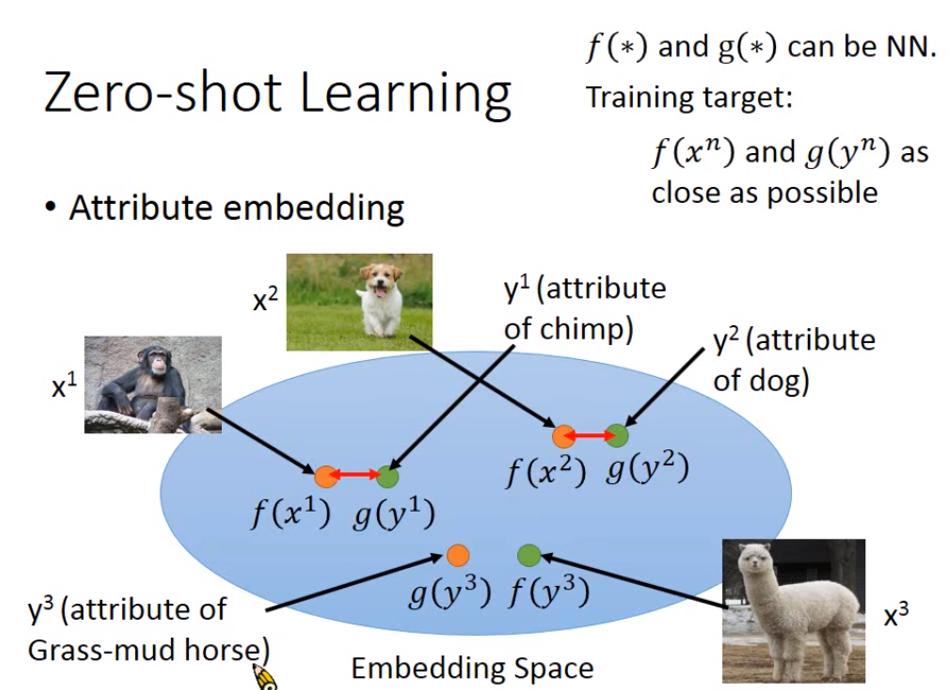
- 將image投射到一個 embedding space上
- 將attribute也投射到同個 embedding space上
- 同張圖片的image和attribute投射之後的位置越近越好
- 不同圖片的f和g不要太近

如果我們根本不知道label要怎麼轉換成attribute呢
- attribute embedding + word embedding(將label變成vector)
只需要 pre-trained model 的 zero-shot learning
例子
- model1: 現成的NN(使用ImageNet訓練)
- model2: word vector model
- model1現在覺得圖片有0.55機率是獅子,另外0.45機率是老虎
- 使用model2得到word vector: V(獅子)以及V(老虎)
- 計算0.55*V(獅子)以及0.45*V(老虎)所在位置
- 發現離它最近位置的word是V(獅虎),故判斷該圖片為獅虎
Zero-Shot Learning by Convex Combination of Semantic Embeddings
文字 domain
machine看過的data
- EK
- KE
- EJ
- JE
能夠得出
- JK
- KJ
Unlabeled Source Data + Labeled Target Data
Self-taught learning
- 用 source data 來 train 一個 feature extractor
- 用 feature extractor 在 target data 上 抽feature